 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracing and segmentation of molecular patterns in 3-dimensional cryo-et/em density maps through algorithmic image processing and deep learning-based techniques
Mar 26, 2024Understanding the structures of biological macromolecules is highly important as they are closely associated with cellular functionalities. Comprehending the precise organization actin filaments is crucial because they form the dynamic cytoskeleton, which offers structural support to cells and connects the cell's interior with its surroundings. However, determining the precise organization of actin filaments is challenging due to the poor quality of cryo-electron tomography (cryo-ET) images, which suffer from low signal-to-noise (SNR) ratios and the presence of missing wedge, as well as diverse shape characteristics of actin filaments. To address these formidable challenges, the primary component of this dissertation focuses on developing sophisticated computational techniques for tracing actin filaments. In particular, three novel methodologies have been developed: i) BundleTrac, for tracing bundle-like actin filaments found in Stereocilium, ii) Spaghetti Tracer, for tracing filaments that move individually with loosely cohesive movements, and iii) Struwwel Tracer, for tracing randomly orientated actin filaments in the actin network. The second component of the dissertation introduces a convolutional neural network (CNN) based segmentation model to determine the location of protein secondary structures, such as helices and beta-sheets, in medium-resolution (5-10 Angstrom) 3-dimensional cryo-electron microscopy (cryo-EM) images. This methodology later evolved into a tool named DeepSSETracer. The final component of the dissertation presents a novel algorithm, cylindrical fit measure, to estimate image structure match at helix regions in medium-resolution cryo-EM images. Overall, my dissertation has made significant contributions to addressing critical research challenges in structural biology by introducing various computational methods and tools.
What factors influence the popularity of user-generated text in the creative domain? A case study of book reviews
Nov 12, 2023
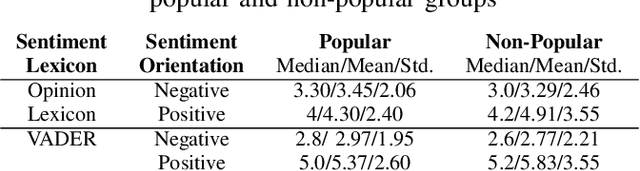
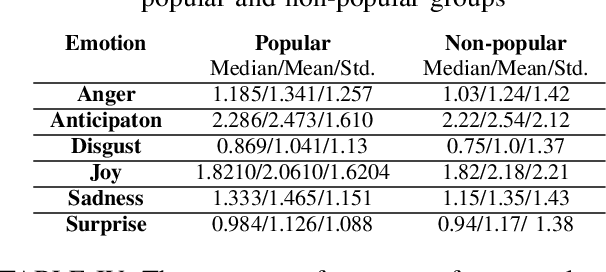
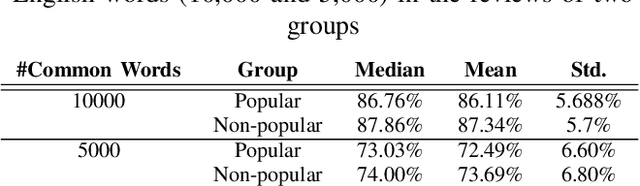
This study investigates a range of psychological, lexical, semantic, and readability features of book reviews to elucidate the factors underlying their perceived popularity. To this end, we conduct statistical analyses of various features, including the types and frequency of opinion and emotion-conveying terms, connectives, character mentions, word uniqueness, commonness, and sentence structure, among others. Additionally, we utilize two readability tests to explore whether reading ease is positively associated with review popularity. Finally, we employ traditional machine learning classifiers and transformer-based fine-tuned language models with n-gram features to automatically determine review popularity. Our findings indicate that, with the exception of a few features (e.g., review length, emotions, and word uniqueness), most attributes do not exhibit significant differences between popular and non-popular review groups. Furthermore, the poor performance of machine learning classifiers using the word n-gram feature highlights the challenges associated with determining popularity in creative domains. Overall, our study provides insights into the factors underlying review popularity and highlights the need for further research in this area, particularly in the creative realm.
Comprehending Lexical and Affective Ontologies in the Demographically Diverse Spatial Social Media Discourse
Nov 12, 2023This study aims to comprehend linguistic and socio-demographic features, encompassing English language styles, conveyed sentiments, and lexical diversity within spatial online social media review data. To this end, we undertake a case study that scrutinizes reviews composed by two distinct and demographically diverse groups. Our analysis entails the extraction and examination of various statistical, grammatical, and sentimental features from these two groups. Subsequently, we leverage these features with machine learning (ML) classifiers to discern their potential in effectively differentiating between the groups. Our investigation unveils substantial disparities in certain linguistic attributes between the two groups. When integrated into ML classifiers, these attributes exhibit a marked efficacy in distinguishing the groups, yielding a macro F1 score of approximately 0.85. Furthermore, we conduct a comparative evaluation of these linguistic features with word n-gram-based lexical features in discerning demographically diverse review data. As expected, the n-gram lexical features, coupled with fine-tuned transformer-based models, show superior performance, attaining accuracies surpassing 95\% and macro F1 scores exceeding 0.96. Our meticulous analysis and comprehensive evaluations substantiate the efficacy of linguistic and sentimental features in effectively discerning demographically diverse review data. The findings of this study provide valuable guidelines for future research endeavors concerning the analysis of demographic patterns in textual content across various social media platforms.
Enhancing Efficiency and Privacy in Memory-Based Malware Classification through Feature Selection
Oct 05, 2023Malware poses a significant security risk to individuals, organizations, and critical infrastructure by compromising systems and data. Leveraging memory dumps that offer snapshots of computer memory can aid the analysis and detection of malicious content, including malware. To improve the efficacy and address privacy concerns in malware classification systems, feature selection can play a critical role as it is capable of identifying the most relevant features, thus, minimizing the amount of data fed to classifiers. In this study, we employ three feature selection approaches to identify significant features from memory content and use them with a diverse set of classifiers to enhance the performance and privacy of the classification task. Comprehensive experiments are conducted across three levels of malware classification tasks: i) binary-level benign or malware classification, ii) malware type classification (including Trojan horse, ransomware, and spyware), and iii) malware family classification within each family (with varying numbers of classes). Results demonstrate that the feature selection strategy, incorporating mutual information and other methods, enhances classifier performance for all tasks. Notably, selecting only 25\% and 50\% of input features using Mutual Information and then employing the Random Forest classifier yields the best results. Our findings reinforce the importance of feature selection for malware classification and provide valuable insights for identifying appropriate approaches. By advancing the effectiveness and privacy of malware classification systems, this research contributes to safeguarding against security threats posed by malicious software.