 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Evolution of Neuron Communities in a Deep Learning Architecture
Jun 08, 2021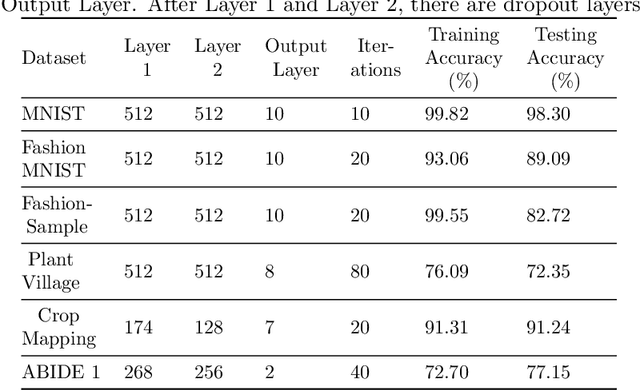



Deep learning techniques are increasingly being adopted for classification tasks over the past decade, yet explaining how deep learning architectures can achieve state-of-the-art performance is still an elusive goal. While all the training information is embedded deeply in a trained model, we still do not understand much about its performance by only analyzing the model. This paper examines the neuron activation patterns of deep learning-based classification models and explores whether the models' performances can be explained through neurons' activation behavior. We propose two approaches: one that models neurons' activation behavior as a graph and examines whether the neurons form meaningful communities, and the other examines the predictability of neurons' behavior using entropy. Our comprehensive experimental study reveals that both the community quality (modularity) and entropy are closely related to the deep learning models' performances, thus paves a novel way of explaining deep learning models directly from the neurons' activation pattern.