 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion-Guided Image to Music Generation
Oct 29, 2024



Generating music from images can enhance various applications, including background music for photo slideshows, social media experiences, and video creation. This paper presents an emotion-guided image-to-music generation framework that leverages the Valence-Arousal (VA) emotional space to produce music that aligns with the emotional tone of a given image. Unlike previous models that rely on contrastive learning for emotional consistency, the proposed approach directly integrates a VA loss function to enable accurate emotional alignment. The model employs a CNN-Transformer architecture, featuring pre-trained CNN image feature extractors and three Transformer encoders to capture complex, high-level emotional features from MIDI music. Three Transformer decoders refine these features to generate musically and emotionally consistent MIDI sequences. Experimental results on a newly curated emotionally paired image-MIDI dataset demonstrate the proposed model's superior performance across metrics such as Polyphony Rate, Pitch Entropy, Groove Consistency, and loss convergence.
Adversarially Trained Deep Neural Semantic Hashing Scheme for Subjective Search in Fashion Inventory
Jun 30, 2019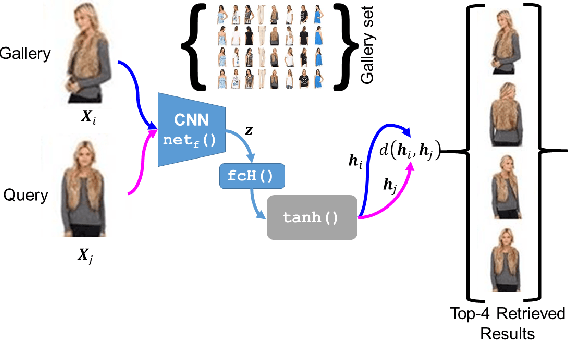



The simple approach of retrieving a closest match of a query image from one in the gallery, compares an image pair using sum of absolute difference in pixel or feature space. The process is computationally expensive, ill-posed to illumination, background composition, pose variation, as well as inefficient to be deployed on gallery sets with more than 1000 elements. Hashing is a faster alternative which involves representing images in reduced dimensional simple feature spaces. Encoding images into binary hash codes enables similarity comparison in an image-pair using the Hamming distance measure. The challenge, however, lies in encoding the images using a semantic hashing scheme that lets subjective neighbors lie within the tolerable Hamming radius. This work presents a solution employing adversarial learning of a deep neural semantic hashing network for fashion inventory retrieval. It consists of a feature extracting convolutional neural network (CNN) learned to (i) minimize error in classifying type of clothing, (ii) minimize hamming distance between semantic neighbors and maximize distance between semantically dissimilar images, (iii) maximally scramble a discriminator's ability to identify the corresponding hash code-image pair when processing a semantically similar query-gallery image pair. Experimental validation for fashion inventory search yields a mean average precision (mAP) of 90.65% in finding the closest match as compared to 53.26% obtained by the prior art of deep Cauchy hashing for hamming space retrieval.