 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Aperture Fusion of Transformer-Convolutional Network (MFTC-Net) for 3D Medical Image Segmentation and Visualization
Jun 24, 2024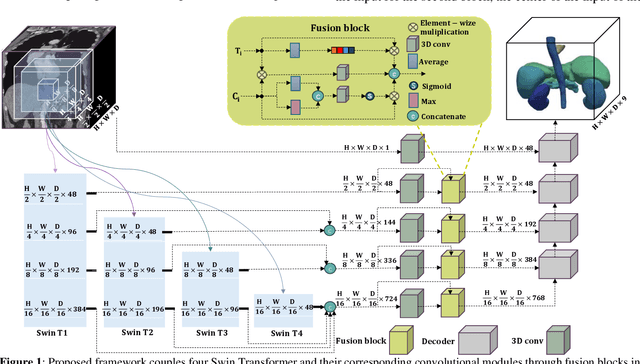
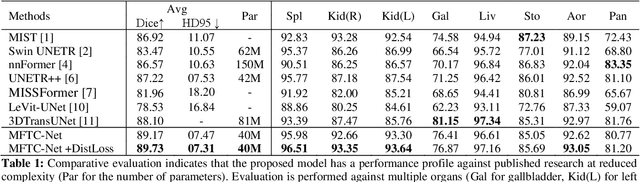
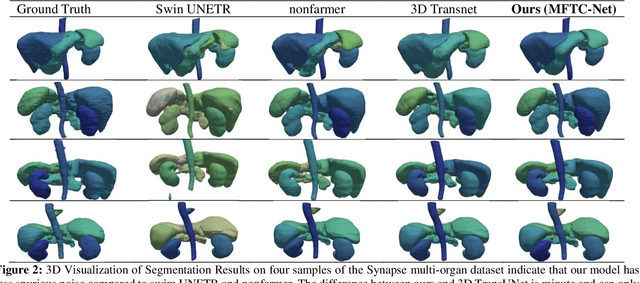

Vision Transformers have shown superior performance to the traditional convolutional-based frameworks in many vision applications, including but not limited to the segmentation of 3D medical images. To further advance this area, this study introduces the Multi-Aperture Fusion of Transformer-Convolutional Network (MFTC-Net), which integrates the output of Swin Transformers and their corresponding convolutional blocks using 3D fusion blocks. The Multi-Aperture incorporates each image patch at its original resolutions with its pyramid representation to better preserve minute details. The proposed architecture has demonstrated a score of 89.73 and 7.31 for Dice and HD95, respectively, on the Synapse multi-organs dataset an improvement over the published results. The improved performance also comes with the added benefits of the reduced complexity of approximately 40 million parameters. Our code is available at https://github.com/Siyavashshabani/MFTC-Net