 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcurrent Validity of Automatic Speech and Pause Measures During Passage Reading in ALS
Aug 22, 2022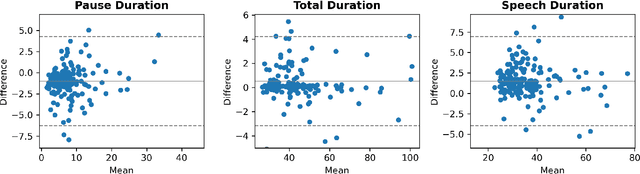
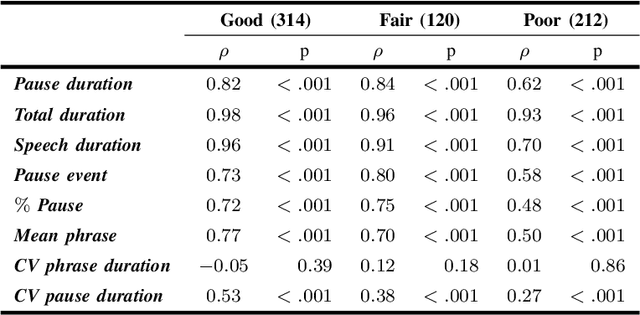
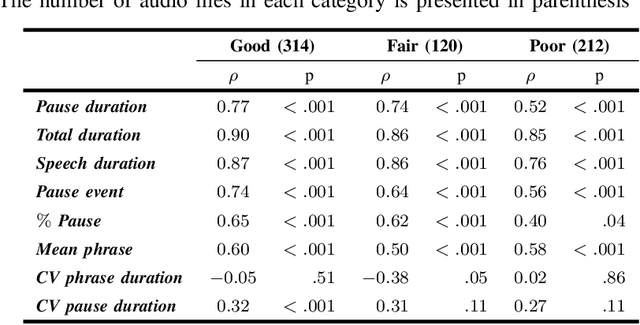
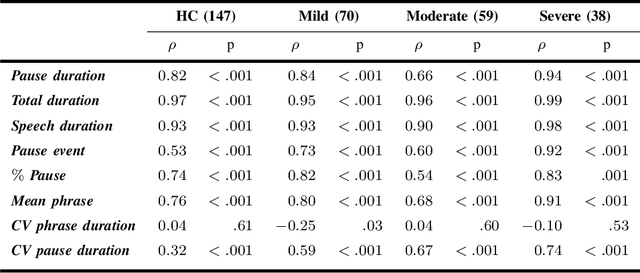
The analysis of speech measures in individuals with amyotrophic lateral sclerosis (ALS) can provide essential information for early diagnosis and tracking disease progression. However, current methods for extracting speech and pause features are manual or semi-automatic, which makes them time-consuming and labour-intensive. The advent of speech-text alignment algorithms provides an opportunity for inexpensive, automated, and accurate analysis of speech measures in individuals with ALS. There is a need to validate speech and pause features calculated by these algorithms against current gold standard methods. In this study, we extracted 8 speech/pause features from 646 audio files of individuals with ALS and healthy controls performing passage reading. Two pretrained forced alignment models - one using transformers and another using a Gaussian mixture / hidden Markov architecture - were used for automatic feature extraction. The results were then validated against semi-automatic speech/pause analysis software, with further subgroup analyses based on audio quality and disease severity. Features extracted using transformer-based forced alignment had the highest agreement with gold standards, including in terms of audio quality and disease severity. This study lays the groundwork for future intelligent diagnostic support systems for clinicians, and for novel methods of tracking disease progression remotely from home.
Automated Temporal Segmentation of Orofacial Assessment Videos
Aug 22, 2022
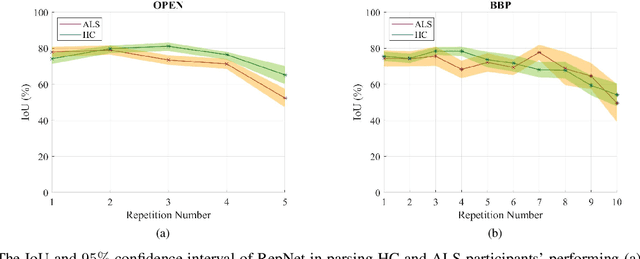
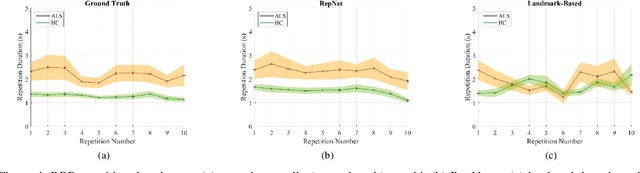
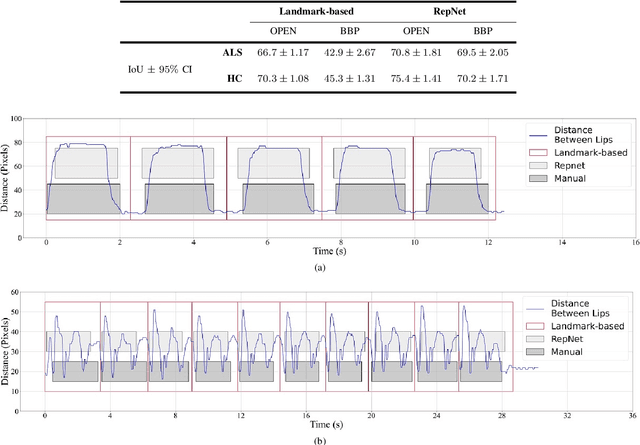
Computer vision techniques can help automate or partially automate clinical examination of orofacial impairments to provide accurate and objective assessments. Towards the development of such automated systems, we evaluated two approaches to detect and temporally segment (parse) repetitions in orofacial assessment videos. Recorded videos of participants with amyotrophic lateral sclerosis (ALS) and healthy control (HC) individuals were obtained from the Toronto NeuroFace Dataset. Two approaches for repetition detection and parsing were examined: one based on engineered features from tracked facial landmarks and peak detection in the distance between the vermilion-cutaneous junction of the upper and lower lips (baseline analysis), and another using a pre-trained transformer-based deep learning model called RepNet (Dwibedi et al, 2020), which automatically detects periodicity, and parses periodic and semi-periodic repetitions in video data. In experimental evaluation of two orofacial assessments tasks, - repeating maximum mouth opening (OPEN) and repeating the sentence "Buy Bobby a Puppy" (BBP) - RepNet provided better parsing than the landmark-based approach, quantified by higher mean intersection-over-union (IoU) with respect to ground truth manual parsing. Automated parsing using RepNet also clearly separated HC and ALS participants based on the duration of BBP repetitions, whereas the landmark-based method could not.