 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Temporal Segmentation of Orofacial Assessment Videos
Paper and Code
Aug 22, 2022
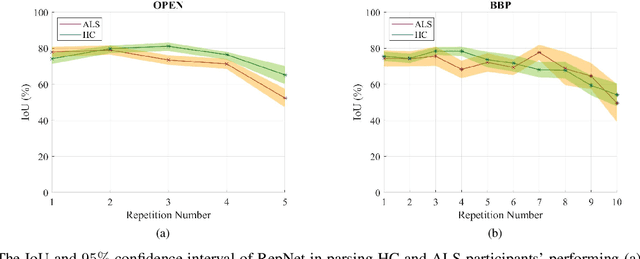
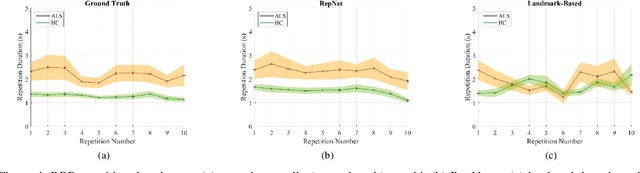
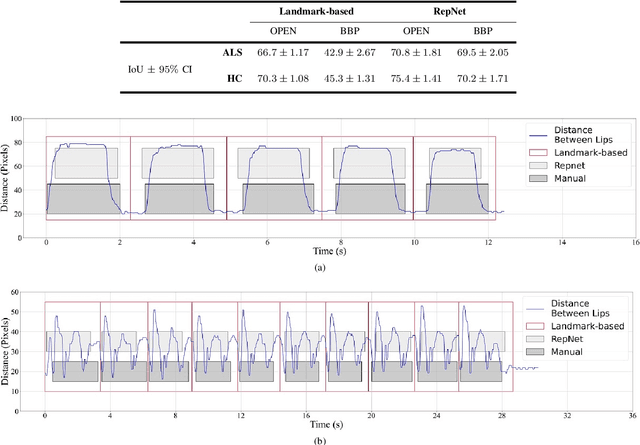
Computer vision techniques can help automate or partially automate clinical examination of orofacial impairments to provide accurate and objective assessments. Towards the development of such automated systems, we evaluated two approaches to detect and temporally segment (parse) repetitions in orofacial assessment videos. Recorded videos of participants with amyotrophic lateral sclerosis (ALS) and healthy control (HC) individuals were obtained from the Toronto NeuroFace Dataset. Two approaches for repetition detection and parsing were examined: one based on engineered features from tracked facial landmarks and peak detection in the distance between the vermilion-cutaneous junction of the upper and lower lips (baseline analysis), and another using a pre-trained transformer-based deep learning model called RepNet (Dwibedi et al, 2020), which automatically detects periodicity, and parses periodic and semi-periodic repetitions in video data. In experimental evaluation of two orofacial assessments tasks, - repeating maximum mouth opening (OPEN) and repeating the sentence "Buy Bobby a Puppy" (BBP) - RepNet provided better parsing than the landmark-based approach, quantified by higher mean intersection-over-union (IoU) with respect to ground truth manual parsing. Automated parsing using RepNet also clearly separated HC and ALS participants based on the duration of BBP repetitions, whereas the landmark-based method could not.