 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Guided CAM: Visual Explanations of Vision Transformer Guided by Self-Attention
Feb 07, 2024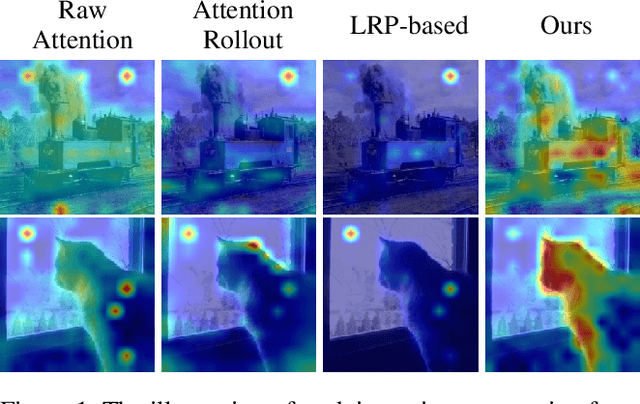



Vision Transformer(ViT) is one of the most widely used models in the computer vision field with its great performance on various tasks. In order to fully utilize the ViT-based architecture in various applications, proper visualization methods with a decent localization performance are necessary, but these methods employed in CNN-based models are still not available in ViT due to its unique structure. In this work, we propose an attention-guided visualization method applied to ViT that provides a high-level semantic explanation for its decision. Our method selectively aggregates the gradients directly propagated from the classification output to each self-attention, collecting the contribution of image features extracted from each location of the input image. These gradients are additionally guided by the normalized self-attention scores, which are the pairwise patch correlation scores. They are used to supplement the gradients on the patch-level context information efficiently detected by the self-attention mechanism. This approach of our method provides elaborate high-level semantic explanations with great localization performance only with the class labels. As a result, our method outperforms the previous leading explainability methods of ViT in the weakly-supervised localization task and presents great capability in capturing the full instances of the target class object. Meanwhile, our method provides a visualization that faithfully explains the model, which is demonstrated in the perturbation comparison test.