 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePresenting a Larger Up-to-date Movie Dataset and Investigating the Effects of Pre-released Attributes on Gross Revenue
Oct 13, 2021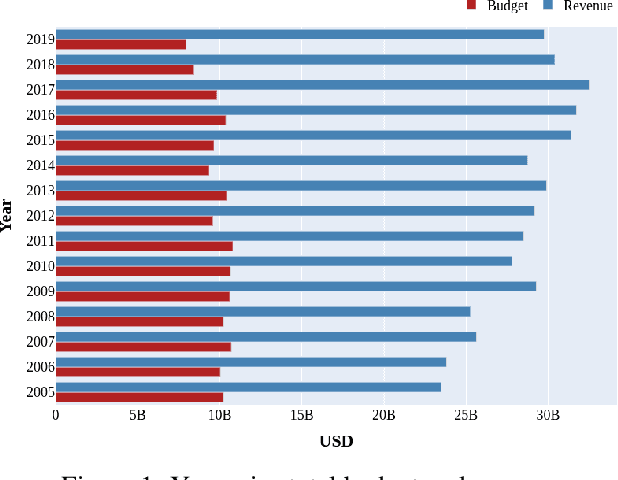
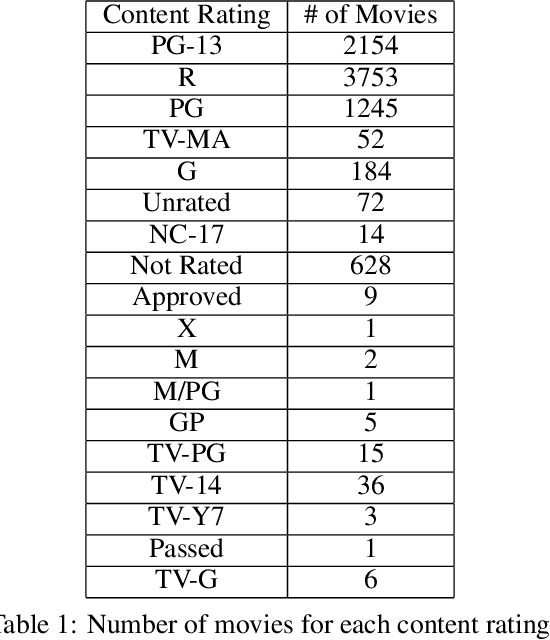
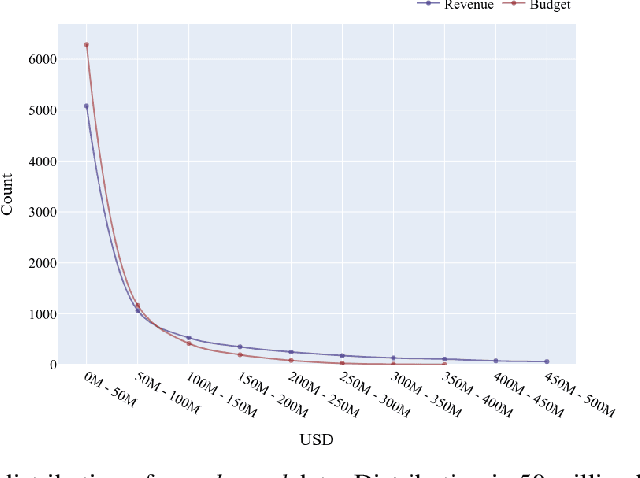

Movie-making has become one of the most costly and risky endeavors in the entertainment industry. Continuous change in the preference of the audience makes it harder to predict what kind of movie will be financially successful at the box office. So, it is no wonder that cautious, intelligent stakeholders and large production houses will always want to know the probable revenue that will be generated by a movie before making an investment. Researchers have been working on finding an optimal strategy to help investors in making the right decisions. But the lack of a large, up-to-date dataset makes their work harder. In this work, we introduce an up-to-date, richer, and larger dataset that we have prepared by scraping IMDb for researchers and data analysts to work with. The compiled dataset contains the summery data of 7.5 million titles and detail information of more than 200K movies. Additionally, we perform different statistical analysis approaches on our dataset to find out how a movie's revenue is affected by different pre-released attributes such as budget, runtime, release month, content rating, genre etc. In our analysis, we have found that having a star cast/director has a positive impact on generated revenue. We introduce a novel approach for calculating the star power of a movie. Based on our analysis we select a set of attributes as features and train different machine learning algorithms to predict a movie's expected revenue. Based on generated revenue, we classified the movies in 10 categories and achieved a one-class-away accuracy rate of almost 60% (bingo accuracy of 30%). All the generated datasets and analysis codes are available online. We also made the source codes of our scraper bots public, so that researchers interested in extending this work can easily modify these bots as they need and prepare their own up-to-date datasets.