 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Mixed Membership Stochastic Block Model for Weighted Labeled Networks
Apr 12, 2023

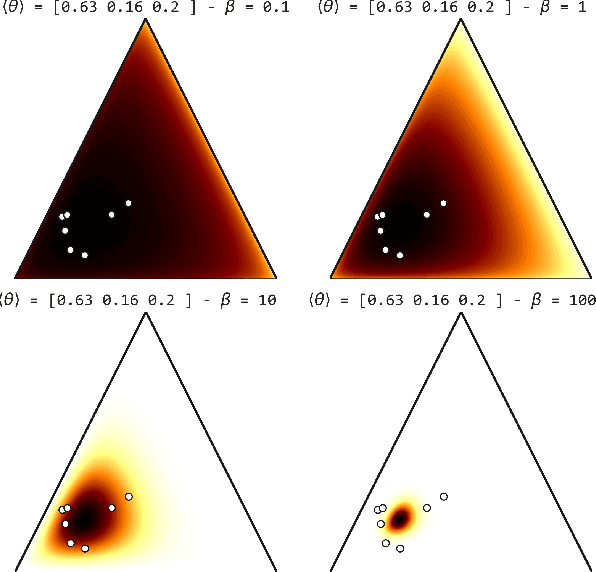
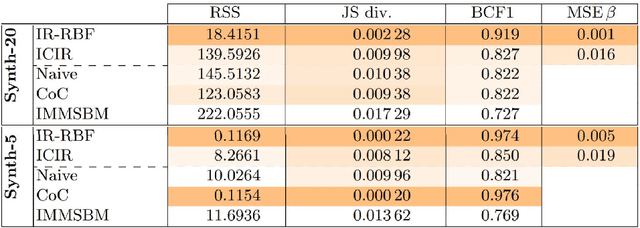
Most real-world networks evolve over time. Existing literature proposes models for dynamic networks that are either unlabeled or assumed to have a single membership structure. On the other hand, a new family of Mixed Membership Stochastic Block Models (MMSBM) allows to model static labeled networks under the assumption of mixed-membership clustering. In this work, we propose to extend this later class of models to infer dynamic labeled networks under a mixed membership assumption. Our approach takes the form of a temporal prior on the model's parameters. It relies on the single assumption that dynamics are not abrupt. We show that our method significantly differs from existing approaches, and allows to model more complex systems --dynamic labeled networks. We demonstrate the robustness of our method with several experiments on both synthetic and real-world datasets. A key interest of our approach is that it needs very few training data to yield good results. The performance gain under challenging conditions broadens the variety of possible applications of automated learning tools --as in social sciences, which comprise many fields where small datasets are a major obstacle to the introduction of machine learning methods.
Multivariate Powered Dirichlet Hawkes Process
Dec 13, 2022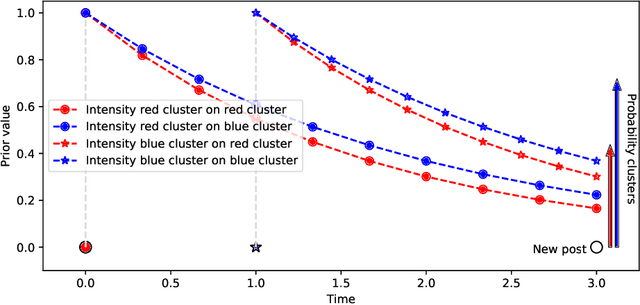
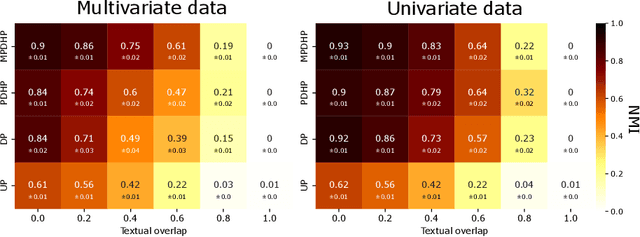
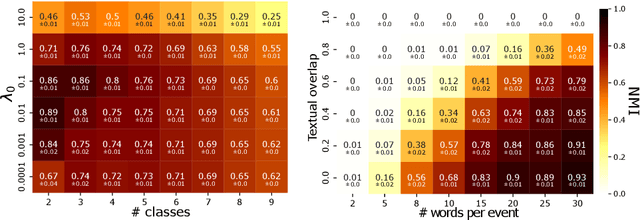
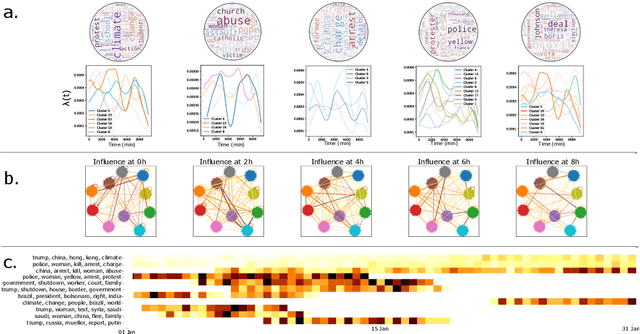
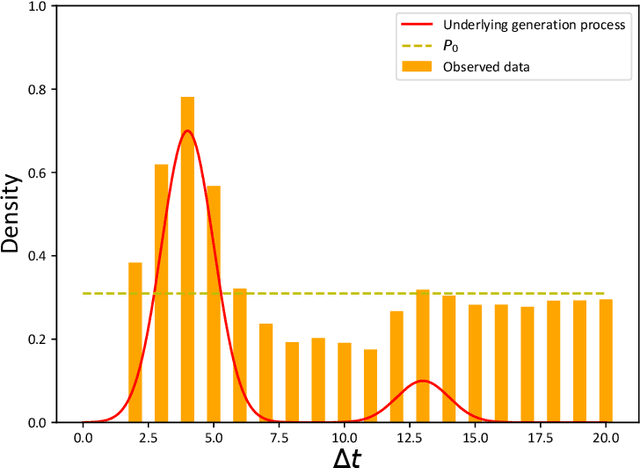
The publication time of a document carries a relevant information about its semantic content. The Dirichlet-Hawkes process has been proposed to jointly model textual information and publication dynamics. This approach has been used with success in several recent works, and extended to tackle specific challenging problems --typically for short texts or entangled publication dynamics. However, the prior in its current form does not allow for complex publication dynamics. In particular, inferred topics are independent from each other --a publication about finance is assumed to have no influence on publications about politics, for instance. In this work, we develop the Multivariate Powered Dirichlet-Hawkes Process (MPDHP), that alleviates this assumption. Publications about various topics can now influence each other. We detail and overcome the technical challenges that arise from considering interacting topics. We conduct a systematic evaluation of MPDHP on a range of synthetic datasets to define its application domain and limitations. Finally, we develop a use case of the MPDHP on Reddit data. At the end of this article, the interested reader will know how and when to use MPDHP, and when not to.
Dirichlet-Survival Process: Scalable Inference of Topic-Dependent Diffusion Networks
Dec 12, 2022Information spread on networks can be efficiently modeled by considering three features: documents' content, time of publication relative to other publications, and position of the spreader in the network. Most previous works model up to two of those jointly, or rely on heavily parametric approaches. Building on recent Dirichlet-Point processes literature, we introduce the Houston (Hidden Online User-Topic Network) model, that jointly considers all those features in a non-parametric unsupervised framework. It infers dynamic topic-dependent underlying diffusion networks in a continuous-time setting along with said topics. It is unsupervised; it considers an unlabeled stream of triplets shaped as \textit{(time of publication, information's content, spreading entity)} as input data. Online inference is conducted using a sequential Monte-Carlo algorithm that scales linearly with the size of the dataset. Our approach yields consequent improvements over existing baselines on both cluster recovery and subnetworks inference tasks.
Properties of Reddit News Topical Interactions
Sep 16, 2022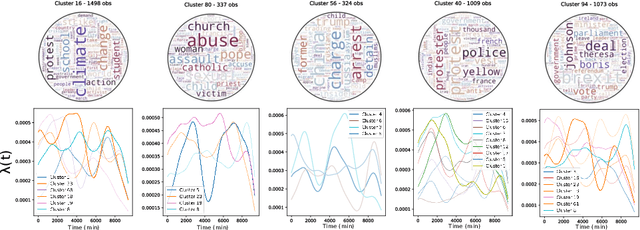
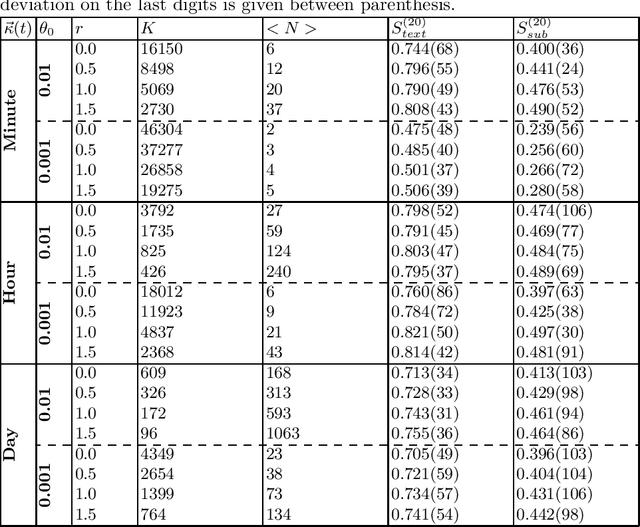
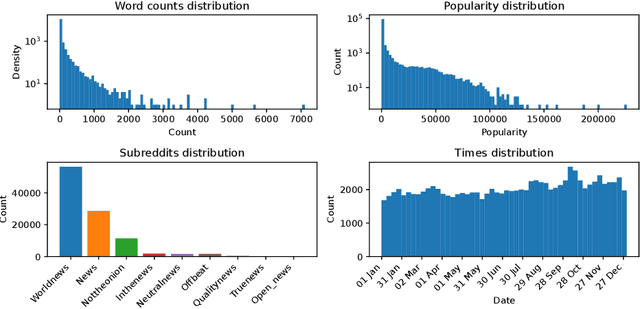

Most models of information diffusion online rely on the assumption that pieces of information spread independently from each other. However, several works pointed out the necessity of investigating the role of interactions in real-world processes, and highlighted possible difficulties in doing so: interactions are sparse and brief. As an answer, recent advances developed models to account for interactions in underlying publication dynamics. In this article, we propose to extend and apply one such model to determine whether interactions between news headlines on Reddit play a significant role in their underlying publication mechanisms. After conducting an in-depth case study on 100,000 news headline from 2019, we retrieve state-of-the-art conclusions about interactions and conclude that they play a minor role in this dataset.
* Published at the conference Complex Networks and their Applications
Serialized Interacting Mixed Membership Stochastic Block Model
Sep 16, 2022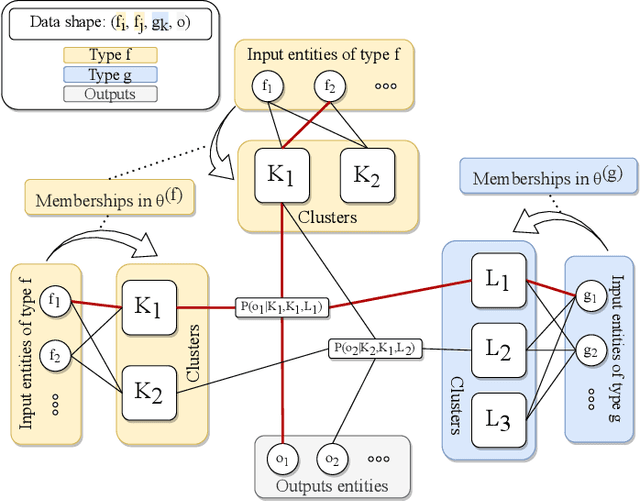


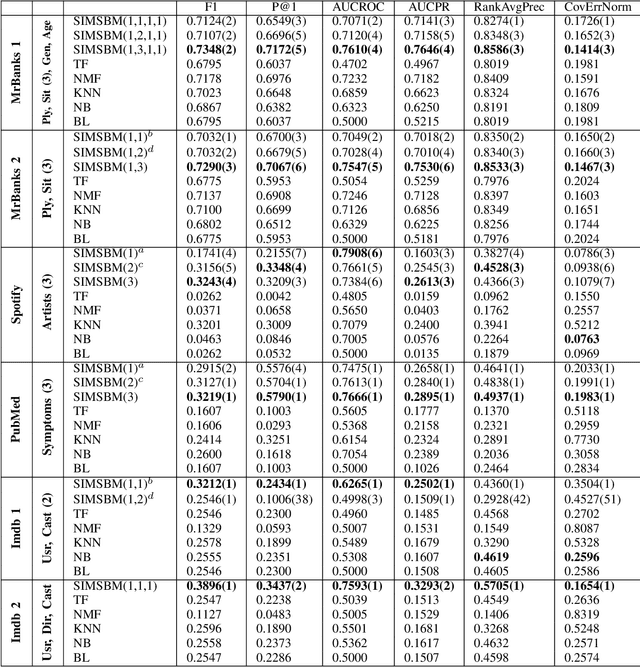
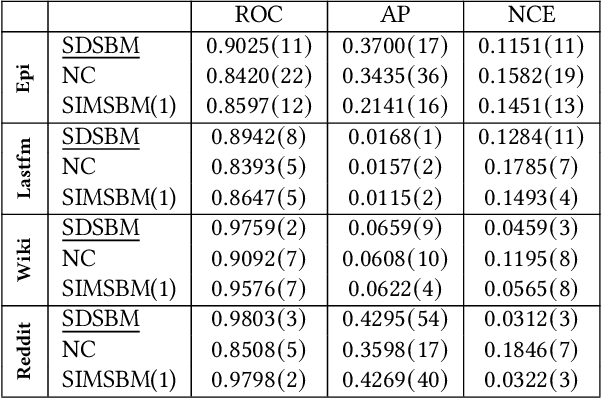
Last years have seen a regain of interest for the use of stochastic block modeling (SBM) in recommender systems. These models are seen as a flexible alternative to tensor decomposition techniques that are able to handle labeled data. Recent works proposed to tackle discrete recommendation problems via SBMs by considering larger contexts as input data and by adding second order interactions between contexts' related elements. In this work, we show that these models are all special cases of a single global framework: the Serialized Interacting Mixed membership Stochastic Block Model (SIMSBM). It allows to model an arbitrarily large context as well as an arbitrarily high order of interactions. We demonstrate that SIMSBM generalizes several recent SBM-based baselines. Besides, we demonstrate that our formulation allows for an increased predictive power on six real-world datasets.
* Published at ICDM 2022
Le Processus Powered Dirichlet-Hawkes comme A Priori Flexible pour Clustering Temporel de Textes
Jan 29, 2022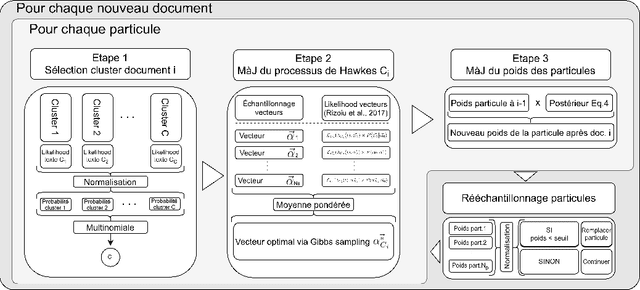
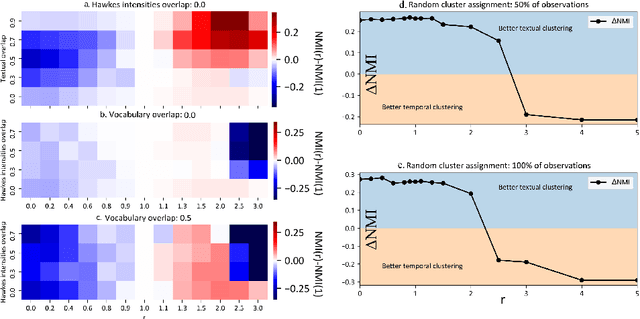
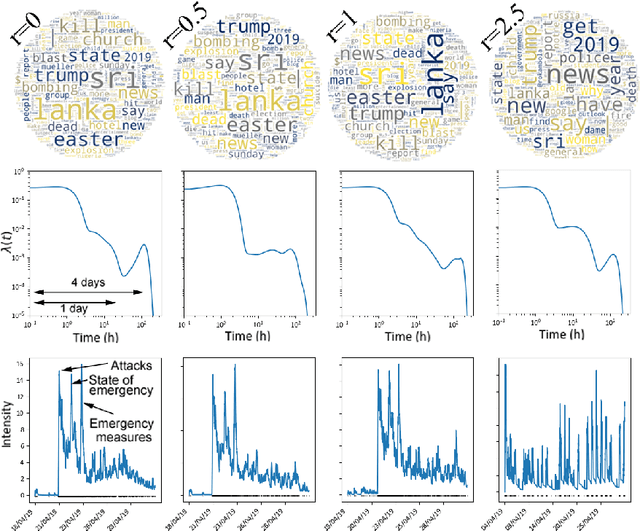
The textual content of a document and its publication date are intertwined. For example, the publication of a news article on a topic is influenced by previous publications on similar issues, according to underlying temporal dynamics. However, it can be challenging to retrieve meaningful information when textual information conveys little. Furthermore, the textual content of a document is not always correlated to its temporal dynamics. We develop a method to create clusters of textual documents according to both their content and publication time, the Powered Dirichlet-Hawkes process (PDHP). PDHP yields significantly better results than state-of-the-art models when temporal information or textual content is weakly informative. PDHP also alleviates the hypothesis that textual content and temporal dynamics are perfectly correlated. We demonstrate that PDHP generalizes previous work --such as DHP and UP. Finally, we illustrate a possible application using a real-world dataset from Reddit.
Powered Hawkes-Dirichlet Process: Challenging Textual Clustering using a Flexible Temporal Prior
Sep 15, 2021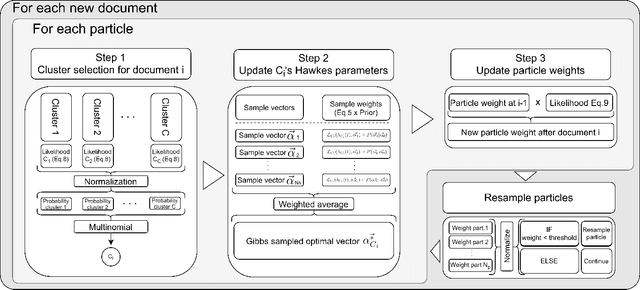

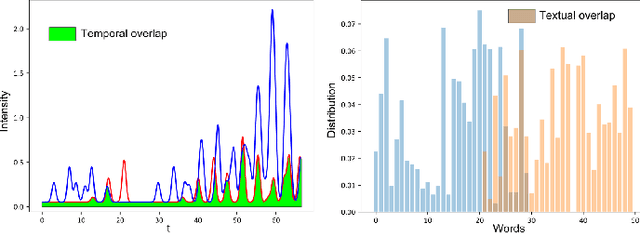

The textual content of a document and its publication date are intertwined. For example, the publication of a news article on a topic is influenced by previous publications on similar issues, according to underlying temporal dynamics. However, it can be challenging to retrieve meaningful information when textual information conveys little information or when temporal dynamics are hard to unveil. Furthermore, the textual content of a document is not always linked to its temporal dynamics. We develop a flexible method to create clusters of textual documents according to both their content and publication time, the Powered Dirichlet-Hawkes process (PDHP). We show PDHP yields significantly better results than state-of-the-art models when temporal information or textual content is weakly informative. The PDHP also alleviates the hypothesis that textual content and temporal dynamics are always perfectly correlated. PDHP allows retrieving textual clusters, temporal clusters, or a mixture of both with high accuracy when they are not. We demonstrate that PDHP generalizes previous work --such as the Dirichlet-Hawkes process (DHP) and Uniform process (UP). Finally, we illustrate the changes induced by PDHP over DHP and UP in a real-world application using Reddit data.
Information Interaction Profile of Choice Adoption
Apr 28, 2021
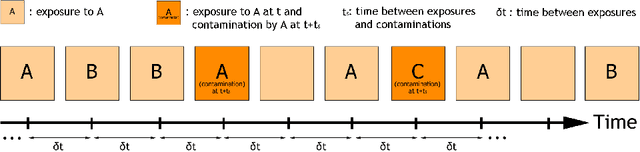
Interactions between pieces of information (entities) play a substantial role in the way an individual acts on them: adoption of a product, the spread of news, strategy choice, etc. However, the underlying interaction mechanisms are often unknown and have been little explored in the literature. We introduce an efficient method to infer both the entities interaction network and its evolution according to the temporal distance separating interacting entities; together, they form the interaction profile. The interaction profile allows characterizing the mechanisms of the interaction processes. We approach this problem via a convex model based on recent advances in multi-kernel inference. We consider an ordered sequence of exposures to entities (URL, ads, situations) and the actions the user exerts on them (share, click, decision). We study how users exhibit different behaviors according to combinations of exposures they have been exposed to. We show that the effect of a combination of exposures on a user is more than the sum of each exposure's independent effect--there is an interaction. We reduce this modeling to a non-parametric convex optimization problem that can be solved in parallel. Our method recovers state-of-the-art results on interaction processes on three real-world datasets and outperforms baselines in the inference of the underlying data generation mechanisms. Finally, we show that interaction profiles can be visualized intuitively, easing the interpretation of the model.
Powered Dirichlet Process for Controlling the Importance of "Rich-Get-Richer" Prior Assumptions in Bayesian Clustering
Apr 26, 2021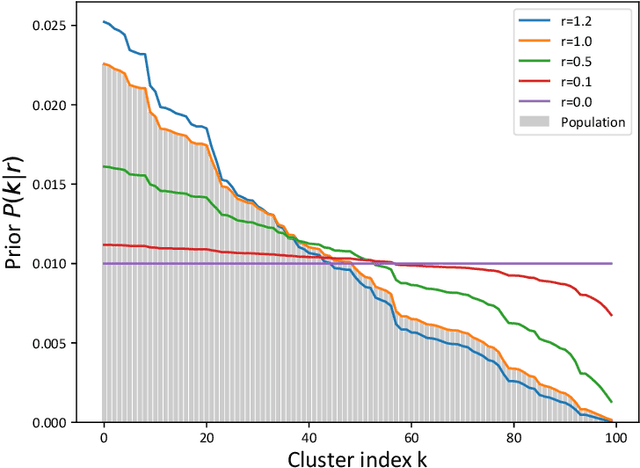
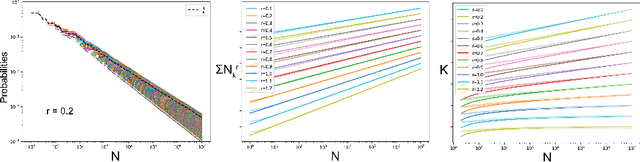
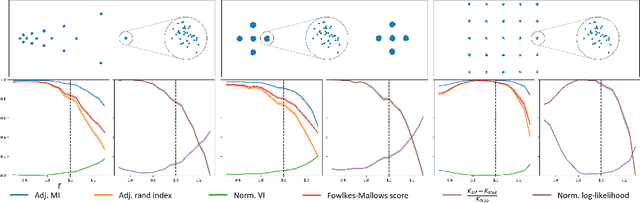
One of the most used priors in Bayesian clustering is the Dirichlet prior. It can be expressed as a Chinese Restaurant Process. This process allows nonparametric estimation of the number of clusters when partitioning datasets. Its key feature is the "rich-get-richer" property, which assumes a cluster has an a priori probability to get chosen linearly dependent on population. In this paper, we show that such prior is not always the best choice to model data. We derive the Powered Chinese Restaurant process from a modified version of the Dirichlet-Multinomial distribution to answer this problem. We then develop some of its fundamental properties (expected number of clusters, convergence). Unlike state-of-the-art efforts in this direction, this new formulation allows for direct control of the importance of the "rich-get-richer" prior.
Interactions in information spread: quantification and interpretation using stochastic block models
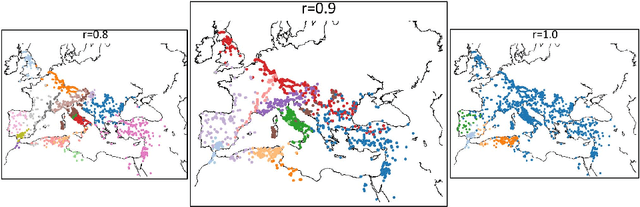
Apr 09, 2020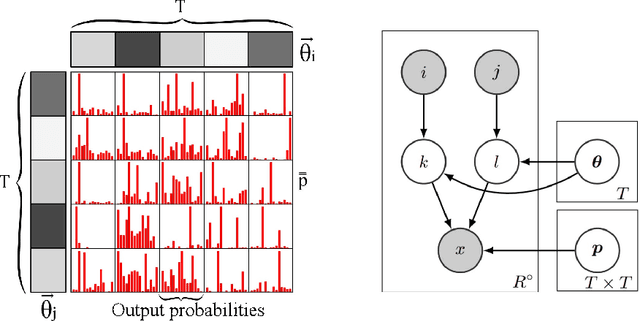
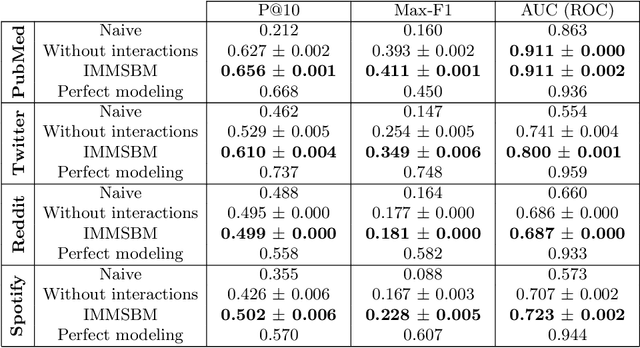
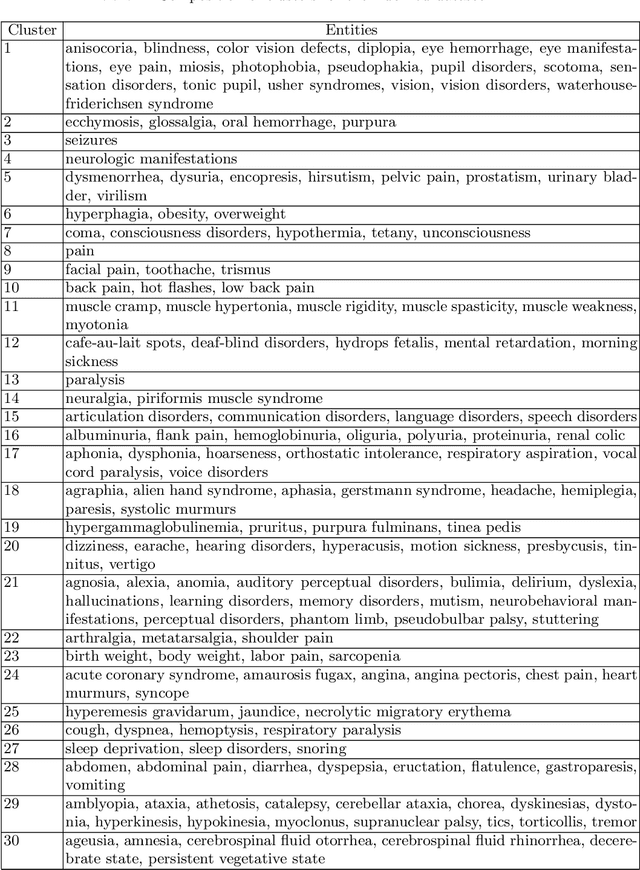
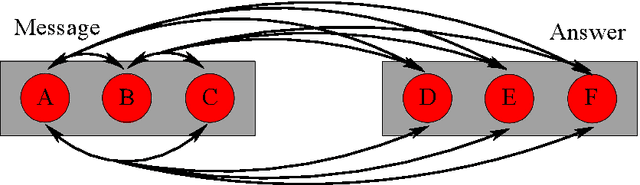
In most real-world applications, it is seldom the case that a given observable evolves independently of its environment. In social networks, users' behavior results from the people they interact with, news in their feed, or trending topics. In natural language, the meaning of phrases emerges from the combination of words. In general medicine, a diagnosis is established on the basis of the interaction of symptoms. Here, we propose a new model, the Interactive Mixed Membership Stochastic Block Model (IMMSBM), which investigates the role of interactions between entities (hashtags, words, memes, etc.) and quantifies their importance within the aforementioned corpora. We find that interactions play an important role in those corpora. In inference tasks, taking them into account leads to average relative changes with respect to non-interactive models of up to 150\% in the probability of an outcome. Furthermore, their role greatly improves the predictive power of the model. Our findings suggest that neglecting interactions when modeling real-world phenomena might lead to incorrect conclusions being drawn.