 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Task Cross-Task Learning Architecture for Ad-hoc Uncertainty Estimation in 3D Cardiac MRI Image Segmentation
Oct 03, 2021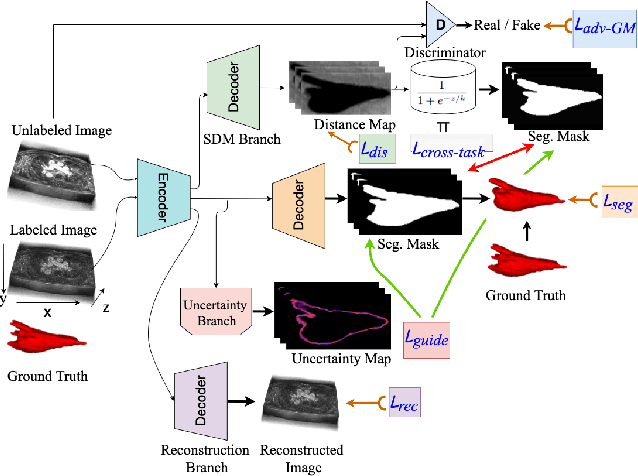

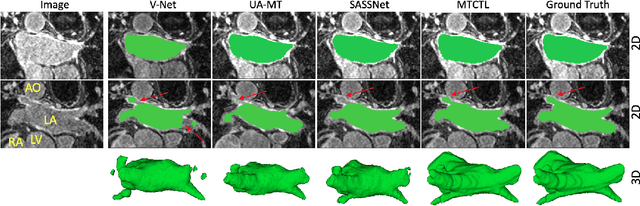
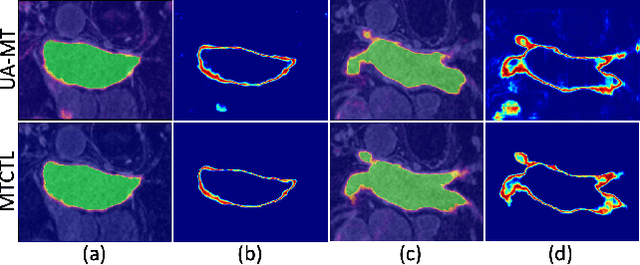
Medical image segmentation has significantly benefitted thanks to deep learning architectures. Furthermore, semi-supervised learning (SSL) has recently been a growing trend for improving a model's overall performance by leveraging abundant unlabeled data. Moreover, learning multiple tasks within the same model further improves model generalizability. To generate smoother and accurate segmentation masks from 3D cardiac MR images, we present a Multi-task Cross-task learning consistency approach to enforce the correlation between the pixel-level (segmentation) and the geometric-level (distance map) tasks. Our extensive experimentation with varied quantities of labeled data in the training sets justifies the effectiveness of our model for the segmentation of the left atrial cavity from Gadolinium-enhanced magnetic resonance (GE-MR) images. With the incorporation of uncertainty estimates to detect failures in the segmentation masks generated by CNNs, our study further showcases the potential of our model to flag low-quality segmentation from a given model.
L-CO-Net: Learned Condensation-Optimization Network for Clinical Parameter Estimation from Cardiac Cine MRI
Apr 21, 2020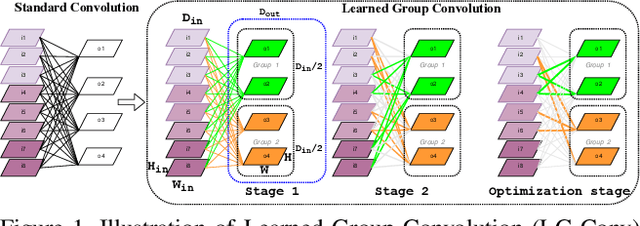
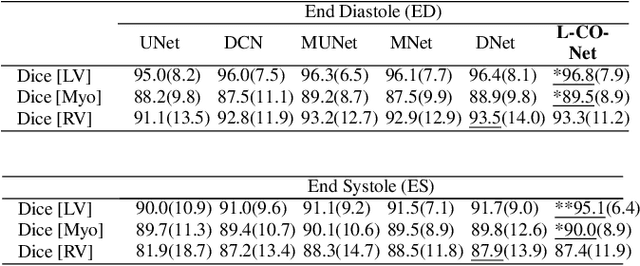
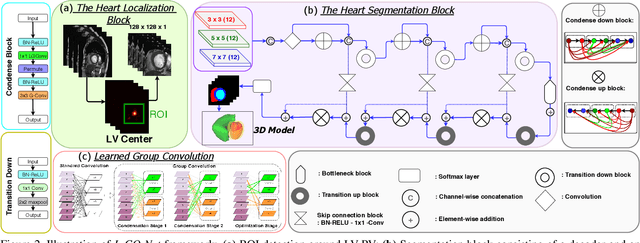
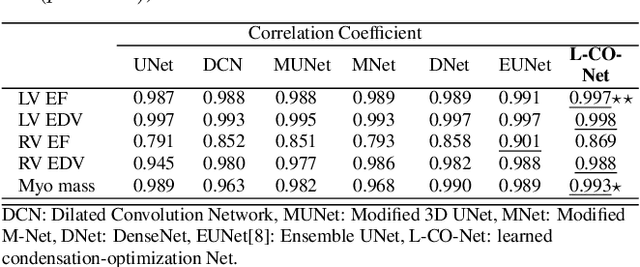
In this work, we implement a fully convolutional segmenter featuring both a learned group structure and a regularized weight-pruner to reduce the high computational cost in volumetric image segmentation. We validated our framework on the ACDC dataset featuring one healthy and four pathology groups imaged throughout the cardiac cycle. Our technique achieved Dice scores of 96.8% (LV blood-pool), 93.3% (RV blood-pool) and 90.0% (LV Myocardium) with five-fold cross-validation and yielded similar clinical parameters as those estimated from the ground truth segmentation data. Based on these results, this technique has the potential to become an efficient and competitive cardiac image segmentation tool that may be used for cardiac computer-aided diagnosis, planning, and guidance applications.
CondenseUNet: A Memory-Efficient Condensely-Connected Architecture for Bi-ventricular Blood Pool and Myocardium Segmentation
Apr 05, 2020



With the advent of Cardiac Cine Magnetic Resonance (CMR) Imaging, there has been a paradigm shift in medical technology, thanks to its capability of imaging different structures within the heart without ionizing radiation. However, it is very challenging to conduct pre-operative planning of minimally invasive cardiac procedures without accurate segmentation and identification of the left ventricle (LV), right ventricle (RV) blood-pool, and LV-myocardium. Manual segmentation of those structures, nevertheless, is time-consuming and often prone to error and biased outcomes. Hence, automatic and computationally efficient segmentation techniques are paramount. In this work, we propose a novel memory-efficient Convolutional Neural Network (CNN) architecture as a modification of both CondenseNet, as well as DenseNet for ventricular blood-pool segmentation by introducing a bottleneck block and an upsampling path. Our experiments show that the proposed architecture runs on the Automated Cardiac Diagnosis Challenge (ACDC) dataset using half (50%) the memory requirement of DenseNet and one-twelfth (~ 8%) of the memory requirements of U-Net, while still maintaining excellent accuracy of cardiac segmentation. We validated the framework on the ACDC dataset featuring one healthy and four pathology groups whose heart images were acquired throughout the cardiac cycle and achieved the mean dice scores of 96.78% (LV blood-pool), 93.46% (RV blood-pool) and 90.1% (LV-Myocardium). These results are promising and promote the proposed methods as a competitive tool for cardiac image segmentation and clinical parameter estimation that has the potential to provide fast and accurate results, as needed for pre-procedural planning and/or pre-operative applications.
U-NetPlus: A Modified Encoder-Decoder U-Net Architecture for Semantic and Instance Segmentation of Surgical Instrument
Feb 24, 2019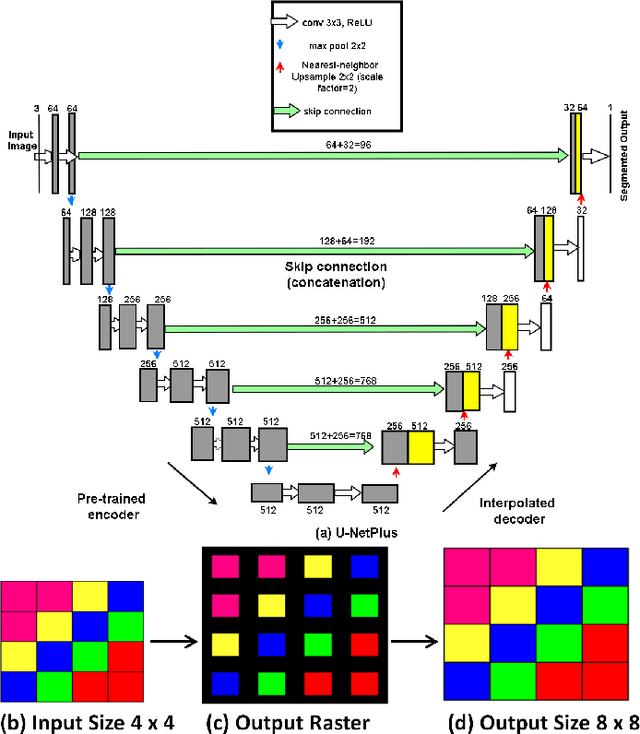
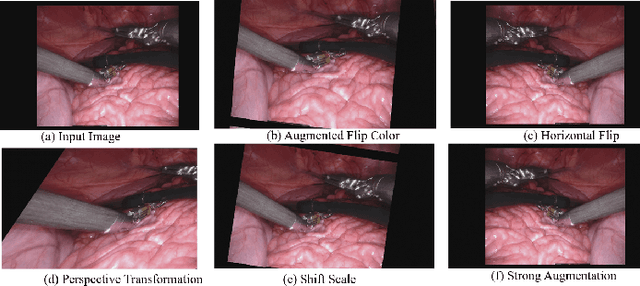
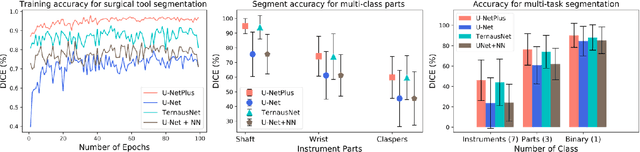
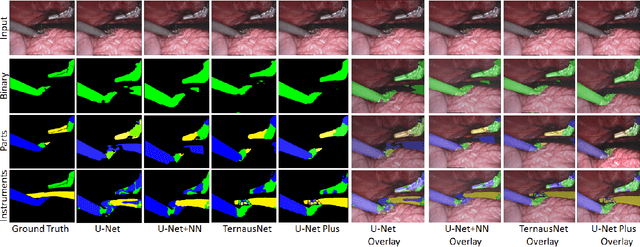
Conventional therapy approaches limit surgeons' dexterity control due to limited field-of-view. With the advent of robot-assisted surgery, there has been a paradigm shift in medical technology for minimally invasive surgery. However, it is very challenging to track the position of the surgical instruments in a surgical scene, and accurate detection & identification of surgical tools is paramount. Deep learning-based semantic segmentation in frames of surgery videos has the potential to facilitate this task. In this work, we modify the U-Net architecture named U-NetPlus, by introducing a pre-trained encoder and re-design the decoder part, by replacing the transposed convolution operation with an upsampling operation based on nearest-neighbor (NN) interpolation. To further improve performance, we also employ a very fast and flexible data augmentation technique. We trained the framework on 8 x 225 frame sequences of robotic surgical videos, available through the MICCAI 2017 EndoVis Challenge dataset and tested it on 8 x 75 frame and 2 x 300 frame videos. Using our U-NetPlus architecture, we report a 90.20% DICE for binary segmentation, 76.26% DICE for instrument part segmentation, and 46.07% for instrument type (i.e., all instruments) segmentation, outperforming the results of previous techniques implemented and tested on these data.