 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage fusion using symmetric skip autoencodervia an Adversarial Regulariser
Jun 04, 2020
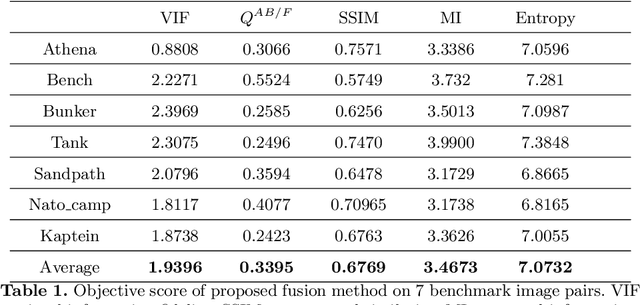
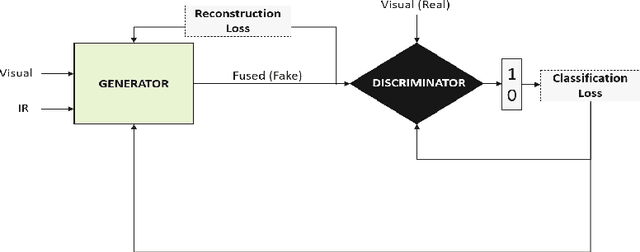
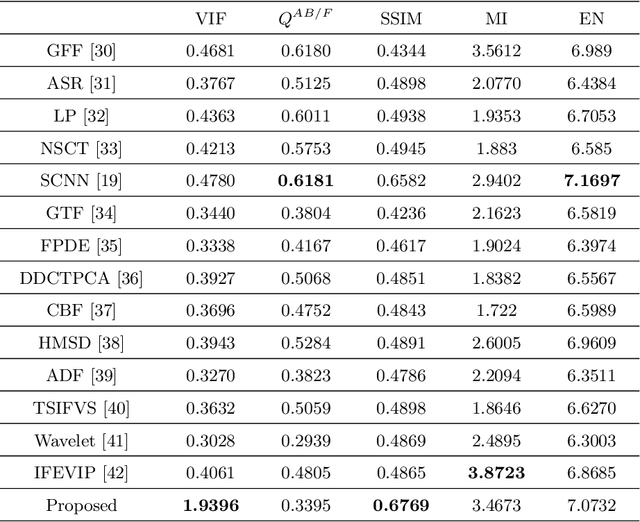
It is a challenging task to extract the best of both worlds by combining the spatial characteristics of a visible image and the spectral content of an infrared image. In this work, we propose a spatially constrained adversarial autoencoder that extracts deep features from the infrared and visible images to obtain a more exhaustive and global representation. In this paper, we propose a residual autoencoder architecture, regularised by a residual adversarial network, to generate a more realistic fused image. The residual module serves as primary building for the encoder, decoder and adversarial network, as an add on the symmetric skip connections perform the functionality of embedding the spatial characteristics directly from the initial layers of encoder structure to the decoder part of the network. The spectral information in the infrared image is incorporated by adding the feature maps over several layers in the encoder part of the fusion structure, which makes inference on both the visual and infrared images separately. In order to efficiently optimize the parameters of the network, we propose an adversarial regulariser network which would perform supervised learning on the fused image and the original visual image.