 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse recovery with unknown variance: a LASSO-type approach
Nov 05, 2012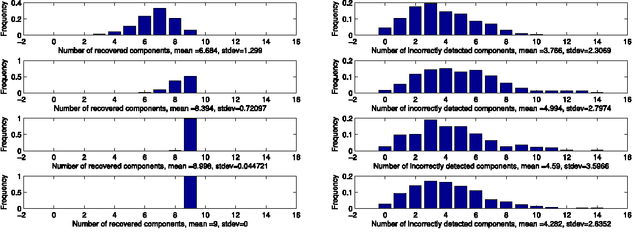
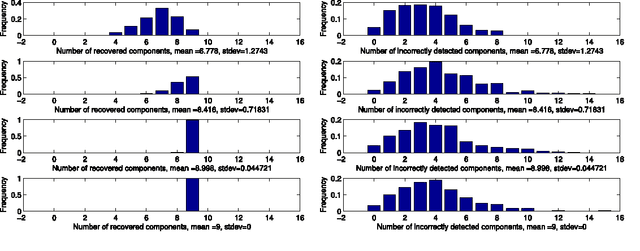
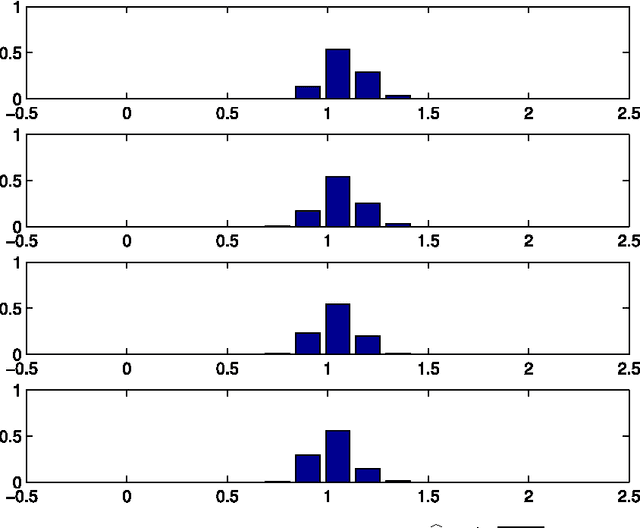
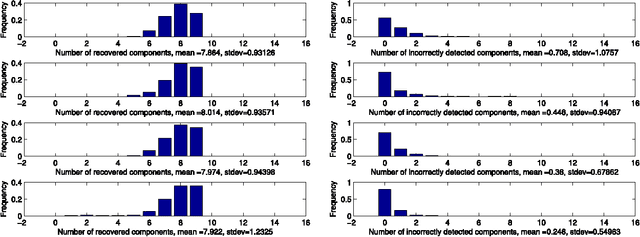
We address the issue of estimating the regression vector $\beta$ in the generic $s$-sparse linear model $y = X\beta+z$, with $\beta\in\R^{p}$, $y\in\R^{n}$, $z\sim\mathcal N(0,\sg^2 I)$ and $p> n$ when the variance $\sg^{2}$ is unknown. We study two LASSO-type methods that jointly estimate $\beta$ and the variance. These estimators are minimizers of the $\ell_1$ penalized least-squares functional, where the relaxation parameter is tuned according to two different strategies. In the first strategy, the relaxation parameter is of the order $\ch{\sigma} \sqrt{\log p}$, where $\ch{\sigma}^2$ is the empirical variance. %The resulting optimization problem can be solved by running only a few successive LASSO instances with %recursive updating of the relaxation parameter. In the second strategy, the relaxation parameter is chosen so as to enforce a trade-off between the fidelity and the penalty terms at optimality. For both estimators, our assumptions are similar to the ones proposed by Cand\`es and Plan in {\it Ann. Stat. (2009)}, for the case where $\sg^{2}$ is known. We prove that our estimators ensure exact recovery of the support and sign pattern of $\beta$ with high probability. We present simulations results showing that the first estimator enjoys nearly the same performances in practice as the standard LASSO (known variance case) for a wide range of the signal to noise ratio. Our second estimator is shown to outperform both in terms of false detection, when the signal to noise ratio is low.