 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemarks on Loss Function of Threshold Method for Ordinal Regression Problem
May 22, 2024



Threshold methods are popular for ordinal regression problems, which are classification problems for data with a natural ordinal relation. They learn a one-dimensional transformation (1DT) of observations of the explanatory variable, and then assign label predictions to the observations by thresholding their 1DT values. In this paper, we study the influence of the underlying data distribution and of the learning procedure of the 1DT on the classification performance of the threshold method via theoretical considerations and numerical experiments. Consequently, for example, we found that threshold methods based on typical learning procedures may perform poorly when the probability distribution of the target variable conditioned on an observation of the explanatory variable tends to be non-unimodal. Another instance of our findings is that learned 1DT values are concentrated at a few points under the learning procedure based on a piecewise-linear loss function, which can make difficult to classify data well.
Parallel Algorithm for Optimal Threshold Labeling of Ordinal Regression Methods
May 21, 2024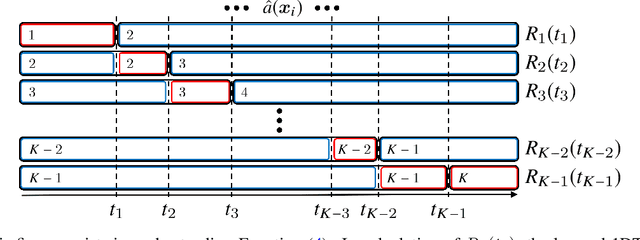

Ordinal regression (OR) is classification of ordinal data in which the underlying categorical target variable has a natural ordinal relation for the underlying explanatory variable. For $K$-class OR tasks, threshold methods learn a one-dimensional transformation (1DT) of the explanatory variable so that 1DT values for observations of the explanatory variable preserve the order of label values $1,\ldots,K$ for corresponding observations of the target variable well, and then assign a label prediction to the learned 1DT through threshold labeling, namely, according to the rank of an interval to which the 1DT belongs among intervals on the real line separated by $(K-1)$ threshold parameters. In this study, we propose a parallelizable algorithm to find the optimal threshold labeling, which was developed in previous research, and derive sufficient conditions for that algorithm to successfully output the optimal threshold labeling. In a numerical experiment we performed, the computation time taken for the whole learning process of a threshold method with the optimal threshold labeling could be reduced to approximately 60\,\% by using the proposed algorithm with parallel processing compared to using an existing algorithm based on dynamic programming.
Convergence Analysis of Blurring Mean Shift
Feb 23, 2024


Blurring mean shift (BMS) algorithm, a variant of the mean shift algorithm, is a kernel-based iterative method for data clustering, where data points are clustered according to their convergent points via iterative blurring. In this paper, we analyze convergence properties of the BMS algorithm by leveraging its interpretation as an optimization procedure, which is known but has been underutilized in existing convergence studies. Whereas existing results on convergence properties applicable to multi-dimensional data only cover the case where all the blurred data point sequences converge to a single point, this study provides a convergence guarantee even when those sequences can converge to multiple points, yielding multiple clusters. This study also shows that the convergence of the BMS algorithm is fast by further leveraging geometrical characterization of the convergent points.
Label Smoothing is Robustification against Model Misspecification
May 15, 2023


Label smoothing (LS) adopts smoothed targets in classification tasks. For example, in binary classification, instead of the one-hot target $(1,0)^\top$ used in conventional logistic regression (LR), LR with LS (LSLR) uses the smoothed target $(1-\frac{\alpha}{2},\frac{\alpha}{2})^\top$ with a smoothing level $\alpha\in(0,1)$, which causes squeezing of values of the logit. Apart from the common regularization-based interpretation of LS that leads to an inconsistent probability estimator, we regard LSLR as modifying the loss function and consistent estimator for probability estimation. In order to study the significance of each of these two modifications by LSLR, we introduce a modified LSLR (MLSLR) that uses the same loss function as LSLR and the same consistent estimator as LR, while not squeezing the logits. For the loss function modification, we theoretically show that MLSLR with a larger smoothing level has lower efficiency with correctly-specified models, while it exhibits higher robustness against model misspecification than LR. Also, for the modification of the probability estimator, an experimental comparison between LSLR and MLSLR showed that this modification and squeezing of the logits in LSLR have negative effects on the probability estimation and classification performance. The understanding of the properties of LS provided by these comparisons allows us to propose MLSLR as an improvement over LSLR.
Convergence Analysis of Mean Shift
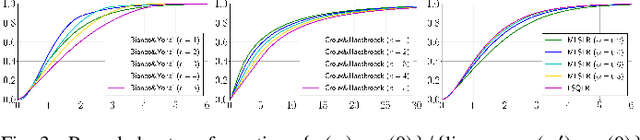
May 15, 2023The mean shift (MS) algorithm seeks a mode of the kernel density estimate (KDE). This study presents a convergence guarantee of the mode estimate sequence generated by the MS algorithm and an evaluation of the convergence rate, under fairly mild conditions, with the help of the argument concerning the {\L}ojasiewicz inequality. Our findings, which extend existing ones covering analytic kernels and the Epanechnikov kernel, are significant in that they cover the biweight kernel that is optimal among non-negative kernels in terms of the asymptotic statistical efficiency for the KDE-based mode estimation.
Optimal Kernel for Kernel-Based Modal Statistical Methods
Apr 20, 2023Kernel-based modal statistical methods include mode estimation, regression, and clustering. Estimation accuracy of these methods depends on the kernel used as well as the bandwidth. We study effect of the selection of the kernel function to the estimation accuracy of these methods. In particular, we theoretically show a (multivariate) optimal kernel that minimizes its analytically-obtained asymptotic error criterion when using an optimal bandwidth, among a certain kernel class defined via the number of its sign changes.
Kernel Selection for Modal Linear Regression: Optimal Kernel and IRLS Algorithm
Jan 30, 2020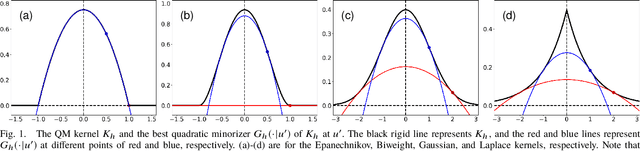
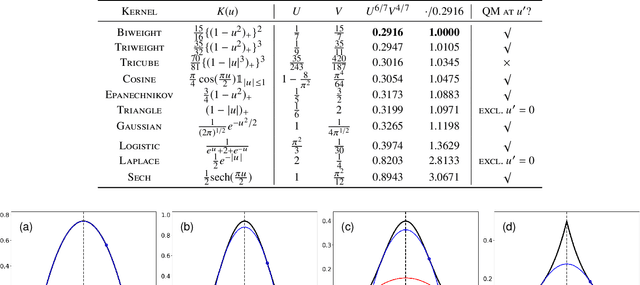

Modal linear regression (MLR) is a method for obtaining a conditional mode predictor as a linear model. We study kernel selection for MLR from two perspectives: "which kernel achieves smaller error?" and "which kernel is computationally efficient?". First, we show that a Biweight kernel is optimal in the sense of minimizing an asymptotic mean squared error of a resulting MLR parameter. This result is derived from our refined analysis of an asymptotic statistical behavior of MLR. Secondly, we provide a kernel class for which iteratively reweighted least-squares algorithm (IRLS) is guaranteed to converge, and especially prove that IRLS with an Epanechnikov kernel terminates in a finite number of iterations. Simulation studies empirically verified that using a Biweight kernel provides good estimation accuracy and that using an Epanechnikov kernel is computationally efficient. Our results improve MLR of which existing studies often stick to a Gaussian kernel and modal EM algorithm specialized for it, by providing guidelines of kernel selection.