 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Pancreatic Cancer Staging with Large Language Models: The Role of Retrieval-Augmented Generation
Mar 19, 2025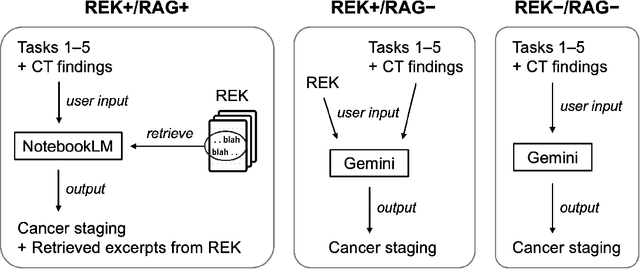
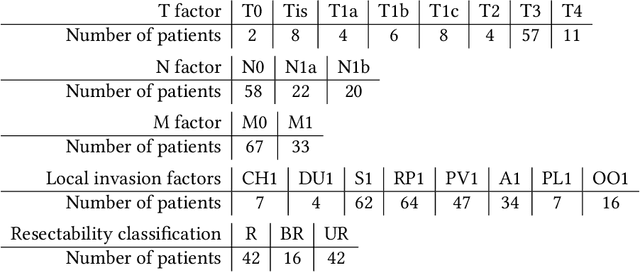
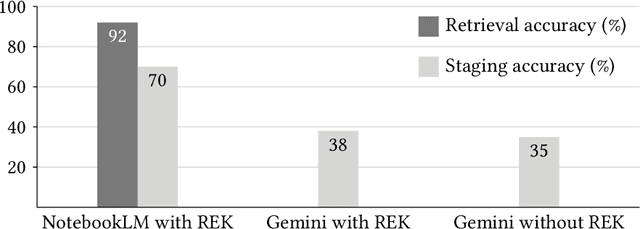
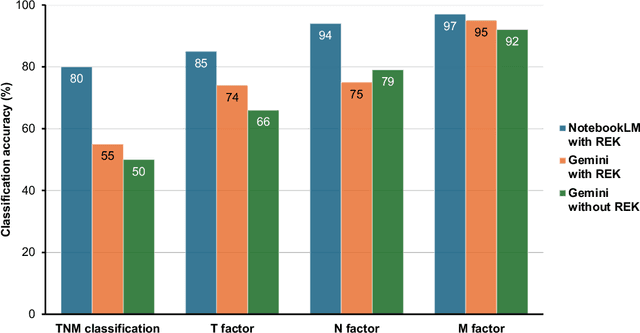
Purpose: Retrieval-augmented generation (RAG) is a technology to enhance the functionality and reliability of large language models (LLMs) by retrieving relevant information from reliable external knowledge (REK). RAG has gained interest in radiology, and we previously reported the utility of NotebookLM, an LLM with RAG (RAG-LLM), for lung cancer staging. However, since the comparator LLM differed from NotebookLM's internal model, it remained unclear whether its advantage stemmed from RAG or inherent model differences. To better isolate RAG's impact and assess its utility across different cancers, we compared NotebookLM with its internal LLM, Gemini 2.0 Flash, in a pancreatic cancer staging experiment. Materials and Methods: A summary of Japan's pancreatic cancer staging guidelines was used as REK. We compared three groups - REK+/RAG+ (NotebookLM with REK), REK+/RAG- (Gemini 2.0 Flash with REK), and REK-/RAG- (Gemini 2.0 Flash without REK) - in staging 100 fictional pancreatic cancer cases based on CT findings. Staging criteria included TNM classification, local invasion factors, and resectability classification. In REK+/RAG+, retrieval accuracy was quantified based on the sufficiency of retrieved REK excerpts. Results: REK+/RAG+ achieved a staging accuracy of 70%, outperforming REK+/RAG- (38%) and REK-/RAG- (35%). For TNM classification, REK+/RAG+ attained 80% accuracy, exceeding REK+/RAG- (55%) and REK-/RAG- (50%). Additionally, REK+/RAG+ explicitly presented retrieved REK excerpts, achieving a retrieval accuracy of 92%. Conclusion: NotebookLM, a RAG-LLM, outperformed its internal LLM, Gemini 2.0 Flash, in a pancreatic cancer staging experiment, suggesting that RAG may improve LLM's staging accuracy. Furthermore, its ability to retrieve and present REK excerpts provides transparency for physicians, highlighting its applicability for clinical diagnosis and classification.
Application of NotebookLM, a Large Language Model with Retrieval-Augmented Generation, for Lung Cancer Staging
Oct 08, 2024Purpose: In radiology, large language models (LLMs), including ChatGPT, have recently gained attention, and their utility is being rapidly evaluated. However, concerns have emerged regarding their reliability in clinical applications due to limitations such as hallucinations and insufficient referencing. To address these issues, we focus on the latest technology, retrieval-augmented generation (RAG), which enables LLMs to reference reliable external knowledge (REK). Specifically, this study examines the utility and reliability of a recently released RAG-equipped LLM (RAG-LLM), NotebookLM, for staging lung cancer. Materials and methods: We summarized the current lung cancer staging guideline in Japan and provided this as REK to NotebookLM. We then tasked NotebookLM with staging 100 fictional lung cancer cases based on CT findings and evaluated its accuracy. For comparison, we performed the same task using a gold-standard LLM, GPT-4 Omni (GPT-4o), both with and without the REK. Results: NotebookLM achieved 86% diagnostic accuracy in the lung cancer staging experiment, outperforming GPT-4o, which recorded 39% accuracy with the REK and 25% without it. Moreover, NotebookLM demonstrated 95% accuracy in searching reference locations within the REK. Conclusion: NotebookLM successfully performed lung cancer staging by utilizing the REK, demonstrating superior performance compared to GPT-4o. Additionally, it provided highly accurate reference locations within the REK, allowing radiologists to efficiently evaluate the reliability of NotebookLM's responses and detect possible hallucinations. Overall, this study highlights the potential of NotebookLM, a RAG-LLM, in image diagnosis.