 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Pancreatic Cancer Staging with Large Language Models: The Role of Retrieval-Augmented Generation
Mar 19, 2025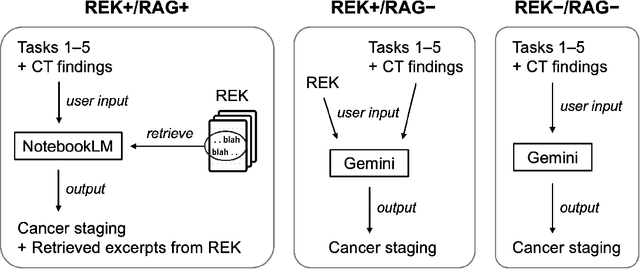
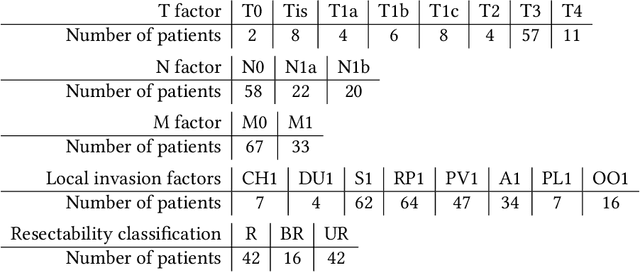
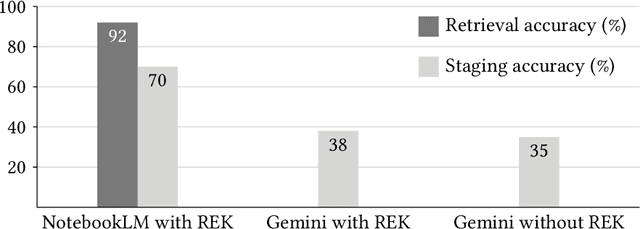
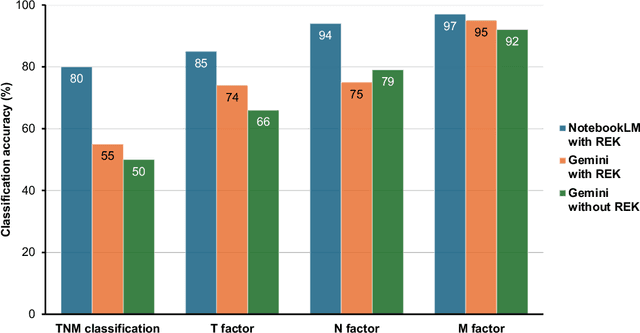
Purpose: Retrieval-augmented generation (RAG) is a technology to enhance the functionality and reliability of large language models (LLMs) by retrieving relevant information from reliable external knowledge (REK). RAG has gained interest in radiology, and we previously reported the utility of NotebookLM, an LLM with RAG (RAG-LLM), for lung cancer staging. However, since the comparator LLM differed from NotebookLM's internal model, it remained unclear whether its advantage stemmed from RAG or inherent model differences. To better isolate RAG's impact and assess its utility across different cancers, we compared NotebookLM with its internal LLM, Gemini 2.0 Flash, in a pancreatic cancer staging experiment. Materials and Methods: A summary of Japan's pancreatic cancer staging guidelines was used as REK. We compared three groups - REK+/RAG+ (NotebookLM with REK), REK+/RAG- (Gemini 2.0 Flash with REK), and REK-/RAG- (Gemini 2.0 Flash without REK) - in staging 100 fictional pancreatic cancer cases based on CT findings. Staging criteria included TNM classification, local invasion factors, and resectability classification. In REK+/RAG+, retrieval accuracy was quantified based on the sufficiency of retrieved REK excerpts. Results: REK+/RAG+ achieved a staging accuracy of 70%, outperforming REK+/RAG- (38%) and REK-/RAG- (35%). For TNM classification, REK+/RAG+ attained 80% accuracy, exceeding REK+/RAG- (55%) and REK-/RAG- (50%). Additionally, REK+/RAG+ explicitly presented retrieved REK excerpts, achieving a retrieval accuracy of 92%. Conclusion: NotebookLM, a RAG-LLM, outperformed its internal LLM, Gemini 2.0 Flash, in a pancreatic cancer staging experiment, suggesting that RAG may improve LLM's staging accuracy. Furthermore, its ability to retrieve and present REK excerpts provides transparency for physicians, highlighting its applicability for clinical diagnosis and classification.
Generating Privacy-Preserving Personalized Advice with Zero-Knowledge Proofs and LLMs
Feb 10, 2025Large language models (LLMs) are increasingly utilized in domains such as finance, healthcare, and interpersonal relationships to provide advice tailored to user traits and contexts. However, this personalization often relies on sensitive data, raising critical privacy concerns and necessitating data minimization. To address these challenges, we propose a framework that integrates zero-knowledge proof (ZKP) technology, specifically zkVM, with LLM-based chatbots. This integration enables privacy-preserving data sharing by verifying user traits without disclosing sensitive information. Our research introduces both an architecture and a prompting strategy for this approach. Through empirical evaluation, we clarify the current constraints and performance limitations of both zkVM and the proposed prompting strategy, thereby demonstrating their practical feasibility in real-world scenarios.