 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacter-level Japanese Text Generation with Attention Mechanism for Chest Radiography Diagnosis
Apr 06, 2020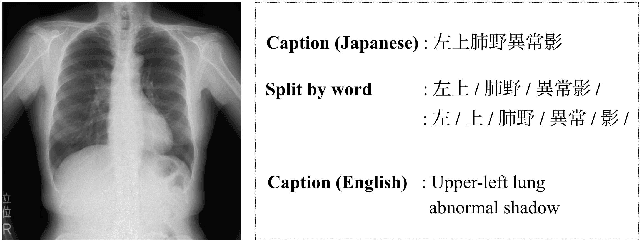

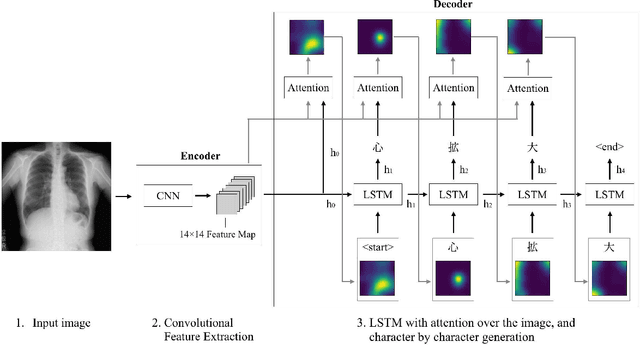
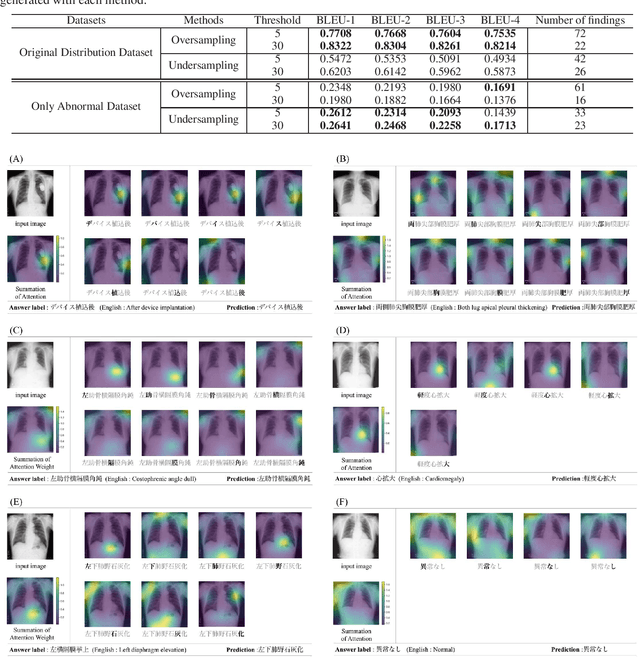
Chest radiography is a general method for diagnosing a patient's condition and identifying important information; therefore, radiography is used extensively in routine medical practice in various situations, such as emergency medical care and medical checkup. However, a high level of expertise is required to interpret chest radiographs. Thus, medical specialists spend considerable time in diagnosing such huge numbers of radiographs. In order to solve these problems, methods for generating findings have been proposed. However, the study of generating chest radiograph findings has primarily focused on the English language, and to the best of our knowledge, no studies have studied Japanese data on this subject. There are two challenges involved in generating findings in the Japanese language. The first challenge is that word splitting is difficult because the boundaries of Japanese word are not clear. The second challenge is that there are numerous orthographic variants. For deal with these two challenges, we proposed an end-to-end model that generates Japanese findings at the character-level from chest radiographs. In addition, we introduced the attention mechanism to improve not only the accuracy, but also the interpretation ability of the results. We evaluated the proposed method using a public dataset with Japanese findings. The effectiveness of the proposed method was confirmed using the Bilingual Evaluation Understudy score. And, we were confirmed from the generated findings that the proposed method was able to consider the orthographic variants. Furthermore, we confirmed via visual inspection that the attention mechanism captures the features and positional information of radiographs.