 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Portfolio Optimization by Predictive Synthesis
Oct 08, 2025Portfolio optimization is a critical task in investment. Most existing portfolio optimization methods require information on the distribution of returns of the assets that make up the portfolio. However, such distribution information is usually unknown to investors. Various methods have been proposed to estimate distribution information, but their accuracy greatly depends on the uncertainty of the financial markets. Due to this uncertainty, a model that could well predict the distribution information at one point in time may perform less accurately compared to another model at a different time. To solve this problem, we investigate a method for portfolio optimization based on Bayesian predictive synthesis (BPS), one of the Bayesian ensemble methods for meta-learning. We assume that investors have access to multiple asset return prediction models. By using BPS with dynamic linear models to combine these predictions, we can obtain a Bayesian predictive posterior about the mean rewards of assets that accommodate the uncertainty of the financial markets. In this study, we examine how to construct mean-variance portfolios and quantile-based portfolios based on the predicted distribution information.
PUATE: Semiparametric Efficient Average Treatment Effect Estimation from Treated (Positive) and Unlabeled Units
Jan 31, 2025The estimation of average treatment effects (ATEs), defined as the difference in expected outcomes between treatment and control groups, is a central topic in causal inference. This study develops semiparametric efficient estimators for ATE estimation in a setting where only a treatment group and an unknown group-comprising units for which it is unclear whether they received the treatment or control-are observable. This scenario represents a variant of learning from positive and unlabeled data (PU learning) and can be regarded as a special case of ATE estimation with missing data. For this setting, we derive semiparametric efficiency bounds, which provide lower bounds on the asymptotic variance of regular estimators. We then propose semiparametric efficient ATE estimators whose asymptotic variance aligns with these efficiency bounds. Our findings contribute to causal inference with missing data and weakly supervised learning.
Active Adaptive Experimental Design for Treatment Effect Estimation with Covariate Choices
Mar 06, 2024

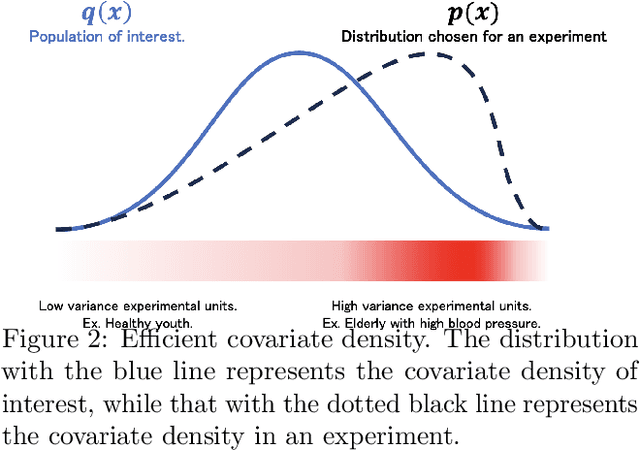

This study designs an adaptive experiment for efficiently estimating average treatment effect (ATEs). We consider an adaptive experiment where an experimenter sequentially samples an experimental unit from a covariate density decided by the experimenter and assigns a treatment. After assigning a treatment, the experimenter observes the corresponding outcome immediately. At the end of the experiment, the experimenter estimates an ATE using gathered samples. The objective of the experimenter is to estimate the ATE with a smaller asymptotic variance. Existing studies have designed experiments that adaptively optimize the propensity score (treatment-assignment probability). As a generalization of such an approach, we propose a framework under which an experimenter optimizes the covariate density, as well as the propensity score, and find that optimizing both covariate density and propensity score reduces the asymptotic variance more than optimizing only the propensity score. Based on this idea, in each round of our experiment, the experimenter optimizes the covariate density and propensity score based on past observations. To design an adaptive experiment, we first derive the efficient covariate density and propensity score that minimizes the semiparametric efficiency bound, a lower bound for the asymptotic variance given a fixed covariate density and a fixed propensity score. Next, we design an adaptive experiment using the efficient covariate density and propensity score sequentially estimated during the experiment. Lastly, we propose an ATE estimator whose asymptotic variance aligns with the minimized semiparametric efficiency bound.