 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-CNN for Facial Micro- and Macro-expression Spotting on Long Video Sequences using Temporal Oriented Reference Frame
Jun 10, 2021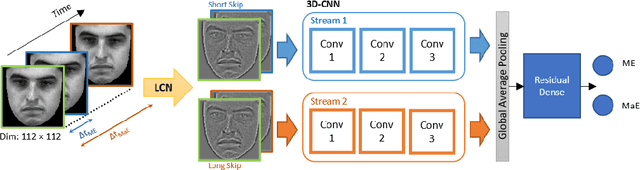
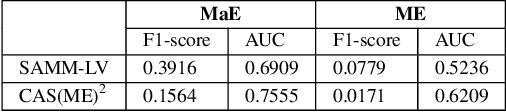
Facial expression spotting is the preliminary step for micro- and macro-expression analysis. The task of reliably spotting such expressions in video sequences is currently unsolved. The current best systems depend upon optical flow methods to extract regional motion features, before categorisation of that motion into a specific class of facial movement. Optical flow is susceptible to drift error, which introduces a serious problem for motions with long-term dependencies, such as high frame-rate macro-expression. We propose a purely deep learning solution which, rather than track frame differential motion, compares via a convolutional model, each frame with two temporally local reference frames. Reference frames are sampled according to calculated micro- and macro-expression durations. We show that our solution achieves state-of-the-art performance (F1-score of 0.126) in a dataset of high frame-rate (200 fps) long video sequences (SAMM-LV) and is competitive in a low frame-rate (30 fps) dataset (CAS(ME)2). In this paper, we document our deep learning model and parameters, including how we use local contrast normalisation, which we show is critical for optimal results. We surpass a limitation in existing methods, and advance the state of deep learning in the domain of facial expression spotting.