 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaultGPT: Industrial Fault Diagnosis Question Answering System by Vision Language Models
Feb 21, 2025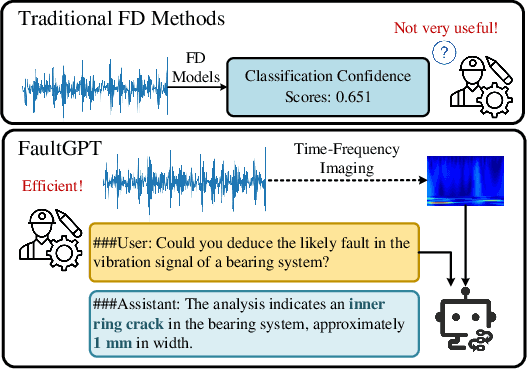
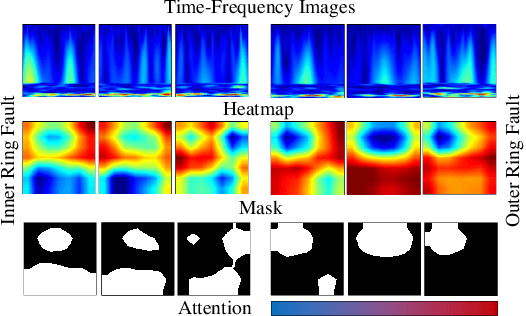
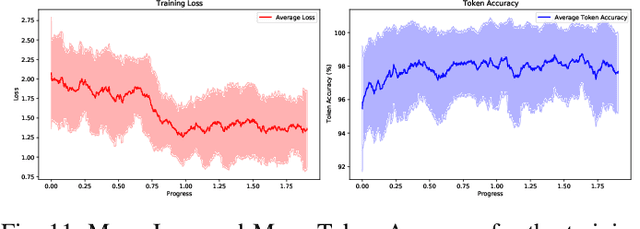
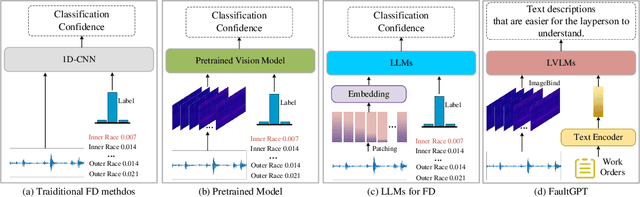
Recently, employing single-modality large language models based on mechanical vibration signals as Tuning Predictors has introduced new perspectives in intelligent fault diagnosis. However, the potential of these methods to leverage multimodal data remains underexploited, particularly in complex mechanical systems where relying on a single data source often fails to capture comprehensive fault information. In this paper, we present FaultGPT, a novel model that generates fault diagnosis reports directly from raw vibration signals. By leveraging large vision-language models (LVLM) and text-based supervision, FaultGPT performs end-to-end fault diagnosis question answering (FDQA), distinguishing itself from traditional classification or regression approaches. Specifically, we construct a large-scale FDQA instruction dataset for instruction tuning of LVLM. This dataset includes vibration time-frequency image-text label pairs and human instruction-ground truth pairs. To enhance the capability in generating high-quality fault diagnosis reports, we design a multi-scale cross-modal image decoder to extract fine-grained fault semantics and conducted instruction tuning without introducing additional training parameters into the LVLM. Extensive experiments, including fault diagnosis report generation, few-shot and zero-shot evaluation across multiple datasets, validate the superior performance and adaptability of FaultGPT in diverse industrial scenarios.