 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting K-means for Big Data by Fusing Data Streaming with Global Optimization
Oct 18, 2024K-means clustering is a cornerstone of data mining, but its efficiency deteriorates when confronted with massive datasets. To address this limitation, we propose a novel heuristic algorithm that leverages the Variable Neighborhood Search (VNS) metaheuristic to optimize K-means clustering for big data. Our approach is based on the sequential optimization of the partial objective function landscapes obtained by restricting the Minimum Sum-of-Squares Clustering (MSSC) formulation to random samples from the original big dataset. Within each landscape, systematically expanding neighborhoods of the currently best (incumbent) solution are explored by reinitializing all degenerate and a varying number of additional centroids. Extensive and rigorous experimentation on a large number of real-world datasets reveals that by transforming the traditional local search into a global one, our algorithm significantly enhances the accuracy and efficiency of K-means clustering in big data environments, becoming the new state of the art in the field.
Superior Parallel Big Data Clustering through Competitive Stochastic Sample Size Optimization in Big-means
Mar 27, 2024

This paper introduces a novel K-means clustering algorithm, an advancement on the conventional Big-means methodology. The proposed method efficiently integrates parallel processing, stochastic sampling, and competitive optimization to create a scalable variant designed for big data applications. It addresses scalability and computation time challenges typically faced with traditional techniques. The algorithm adjusts sample sizes dynamically for each worker during execution, optimizing performance. Data from these sample sizes are continually analyzed, facilitating the identification of the most efficient configuration. By incorporating a competitive element among workers using different sample sizes, efficiency within the Big-means algorithm is further stimulated. In essence, the algorithm balances computational time and clustering quality by employing a stochastic, competitive sampling strategy in a parallel computing setting.
Strategies for Parallelizing the Big-Means Algorithm: A Comprehensive Tutorial for Effective Big Data Clustering
Nov 08, 2023This study focuses on the optimization of the Big-means algorithm for clustering large-scale datasets, exploring four distinct parallelization strategies. We conducted extensive experiments to assess the computational efficiency, scalability, and clustering performance of each approach, revealing their benefits and limitations. The paper also delves into the trade-offs between computational efficiency and clustering quality, examining the impacts of various factors. Our insights provide practical guidance on selecting the best parallelization strategy based on available resources and dataset characteristics, contributing to a deeper understanding of parallelization techniques for the Big-means algorithm.
Optimizing K-means for Big Data: A Comparative Study
Oct 15, 2023This paper presents a comparative analysis of different optimization techniques for the K-means algorithm in the context of big data. K-means is a widely used clustering algorithm, but it can suffer from scalability issues when dealing with large datasets. The paper explores different approaches to overcome these issues, including parallelization, approximation, and sampling methods. The authors evaluate the performance of these techniques on various benchmark datasets and compare them in terms of speed, quality of clustering, and scalability according to the LIMA dominance criterion. The results show that different techniques are more suitable for different types of datasets and provide insights into the trade-offs between speed and accuracy in K-means clustering for big data. Overall, the paper offers a comprehensive guide for practitioners and researchers on how to optimize K-means for big data applications.
Big-means: Less is More for K-means Clustering
Apr 14, 2022
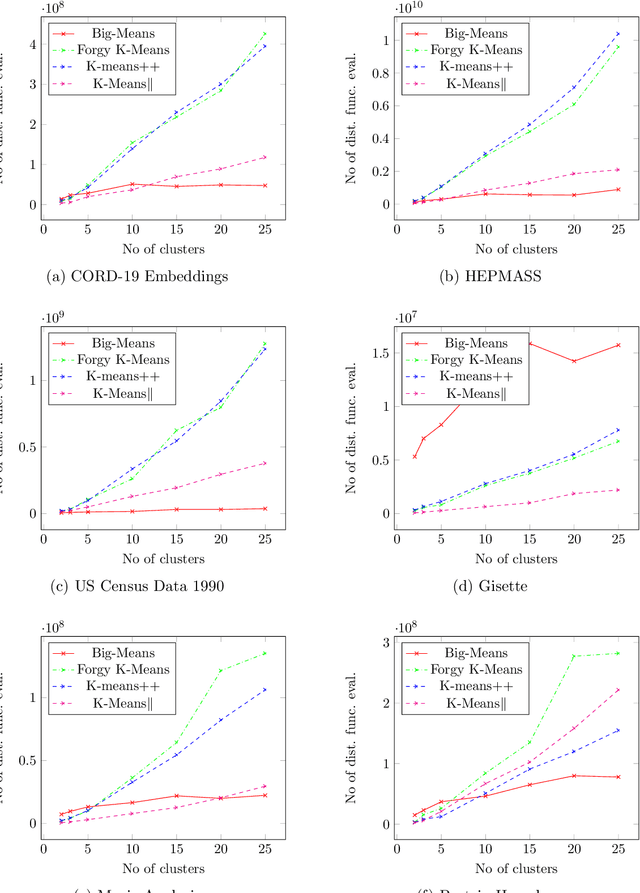

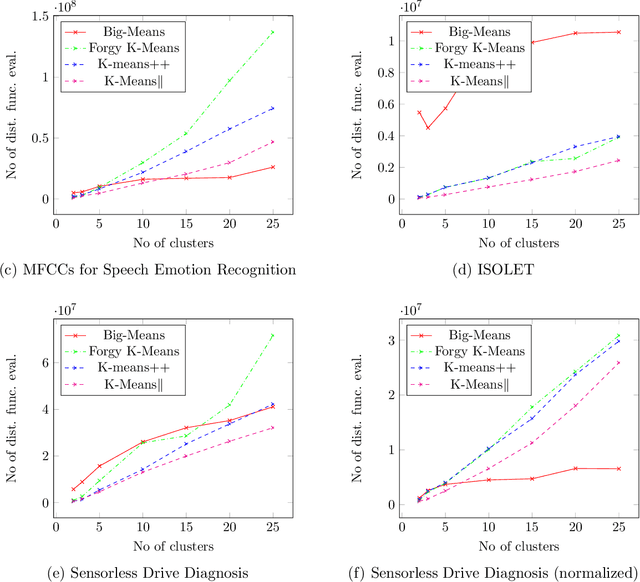
K-means clustering plays a vital role in data mining. However, its performance drastically drops when applied to huge amounts of data. We propose a new heuristic that is built on the basis of regular K-means for faster and more accurate big data clustering using the "less is more" and MSSC decomposition approaches. The main advantage of the proposed algorithm is that it naturally turns the K-means local search into global one through the process of decomposition of the MSSC problem. On one hand, decomposition of the MSSC problem into smaller subproblems reduces the computational complexity and allows for their parallel processing. On the other hand, the MSSC decomposition provides a new method for the natural data-driven shaking of the incumbent solution while introducing a new neighborhood structure for the solution of the MSSC problem. This leads to a new heuristic that improves K-means in big data conditions. The scalability of the algorithm to big data can be easily adjusted by choosing the appropriate number of subproblems and their size. The proposed algorithm is both scalable and accurate. In our experiments it outperforms all recent state-of-the-art algorithms for the MSSC in terms of time as well as the solution quality.
Neural Named Entity Recognition for Kazakh
Jul 17, 2020
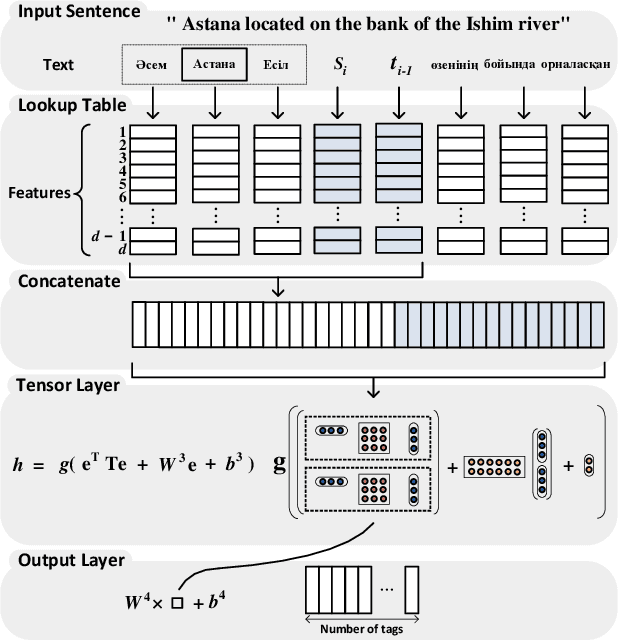
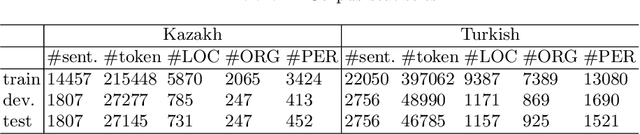
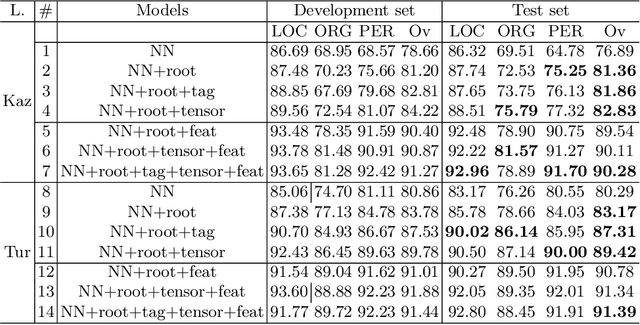
We present several neural networks to address the task of named entity recognition for morphologically complex languages (MCL). Kazakh is a morphologically complex language in which each root/stem can produce hundreds or thousands of variant word forms. This nature of the language could lead to a serious data sparsity problem, which may prevent the deep learning models from being well trained for under-resourced MCLs. In order to model the MCLs' words effectively, we introduce root and entity tag embedding plus tensor layer to the neural networks. The effects of those are significant for improving NER model performance of MCLs. The proposed models outperform state-of-the-art including character-based approaches, and can be potentially applied to other morphologically complex languages.