 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEAT-Net: Injecting Biomimetic Spatio-Temporal Priors for Interpretable ECG Classification
Jan 12, 2026Although deep learning has advanced automated electrocardiogram (ECG) diagnosis, prevalent supervised methods typically treat recordings as undifferentiated one-dimensional (1D) signals or two-dimensional (2D) images. This formulation compels models to learn physiological structures implicitly, resulting in data inefficiency and opacity that diverge from medical reasoning. To address these limitations, we propose BEAT-Net, a Biomimetic ECG Analysis with Tokenization framework that reformulates the problem as a language modeling task. Utilizing a QRS tokenization strategy to transform continuous signals into biologically aligned heartbeat sequences, the architecture explicitly decomposes cardiac physiology through specialized encoders that extract local beat morphology while normalizing spatial lead perspectives and modeling temporal rhythm dependencies. Evaluations across three large-scale benchmarks demonstrate that BEAT-Net matches the diagnostic accuracy of dominant convolutional neural network (CNN) architectures while substantially improving robustness. The framework exhibits exceptional data efficiency, recovering fully supervised performance using only 30 to 35 percent of annotated data. Moreover, learned attention mechanisms provide inherent interpretability by spontaneously reproducing clinical heuristics, such as Lead II prioritization for rhythm analysis, without explicit supervision. These findings indicate that integrating biological priors offers a computationally efficient and interpretable alternative to data-intensive large-scale pre-training.
Stacking-Enhanced Bagging Ensemble Learning for Breast Cancer Classification with CNN
Jul 15, 2024This paper proposes a CNN classification network based on Bagging and stacking ensemble learning methods for breast cancer classification. The model was trained and tested on the public dataset of DDSM. The model is capable of fast and accurate classification of input images. According to our research results, for binary classification (presence or absence of breast cancer), the accuracy reached 98.84%, and for five-class classification, the accuracy reached 98.34%. The model also achieved a micro-average recall rate of 94.80% and an F1 score of 94.19%. In comparative experiments, we compared the effects of different values of bagging_ratio and n_models on the model, as well as several methods for ensemble bagging models. Furthermore, under the same parameter settings, our BSECNN outperformed VGG16 and ResNet-50 in terms of accuracy by 8.22% and 6.33% respectively.
TRIG: Transformer-Based Text Recognizer with Initial Embedding Guidance
Nov 16, 2021
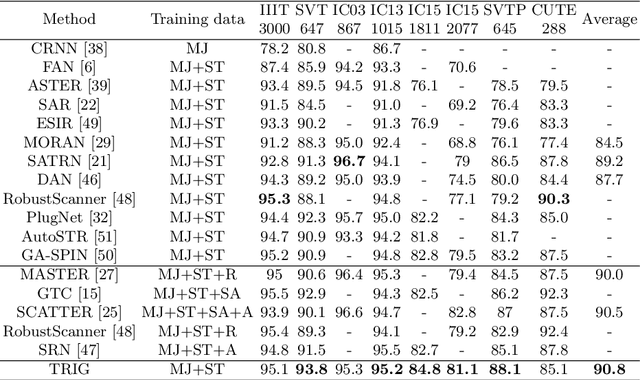
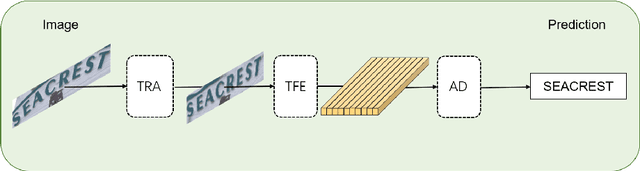
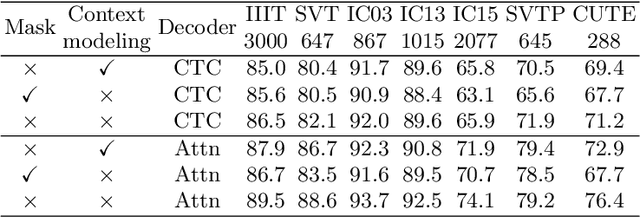
Scene text recognition (STR) is an important bridge between images and text, attracting abundant research attention. While convolutional neural networks (CNNS) have achieved remarkable progress in this task, most of the existing works need an extra module (context modeling module) to help CNN to capture global dependencies to solve the inductive bias and strengthen the relationship between text features. Recently, the transformer has been proposed as a promising network for global context modeling by self-attention mechanism, but one of the main shortcomings, when applied to recognition, is the efficiency. We propose a 1-D split to address the challenges of complexity and replace the CNN with the transformer encoder to reduce the need for a context modeling module. Furthermore, recent methods use a frozen initial embedding to guide the decoder to decode the features to text, leading to a loss of accuracy. We propose to use a learnable initial embedding learned from the transformer encoder to make it adaptive to different input images. Above all, we introduce a novel architecture for text recognition, named TRansformer-based text recognizer with Initial embedding Guidance (TRIG), composed of three stages (transformation, feature extraction, and prediction). Extensive experiments show that our approach can achieve state-of-the-art on text recognition benchmarks.