 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRIG: Transformer-Based Text Recognizer with Initial Embedding Guidance
Paper and Code
Nov 16, 2021
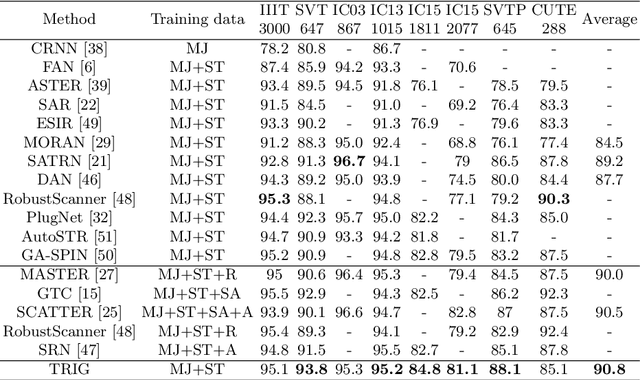
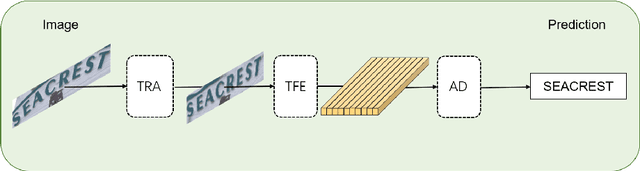
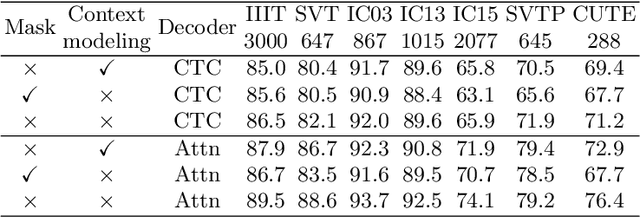
Scene text recognition (STR) is an important bridge between images and text, attracting abundant research attention. While convolutional neural networks (CNNS) have achieved remarkable progress in this task, most of the existing works need an extra module (context modeling module) to help CNN to capture global dependencies to solve the inductive bias and strengthen the relationship between text features. Recently, the transformer has been proposed as a promising network for global context modeling by self-attention mechanism, but one of the main shortcomings, when applied to recognition, is the efficiency. We propose a 1-D split to address the challenges of complexity and replace the CNN with the transformer encoder to reduce the need for a context modeling module. Furthermore, recent methods use a frozen initial embedding to guide the decoder to decode the features to text, leading to a loss of accuracy. We propose to use a learnable initial embedding learned from the transformer encoder to make it adaptive to different input images. Above all, we introduce a novel architecture for text recognition, named TRansformer-based text recognizer with Initial embedding Guidance (TRIG), composed of three stages (transformation, feature extraction, and prediction). Extensive experiments show that our approach can achieve state-of-the-art on text recognition benchmarks.