 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Efficient Language-supervised Zero-shot Recognition with Optimal Transport Distillation
Dec 20, 2021
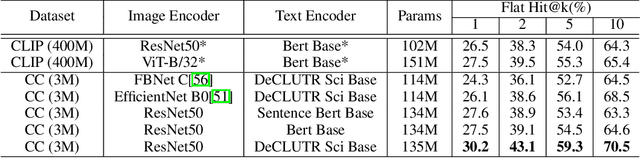
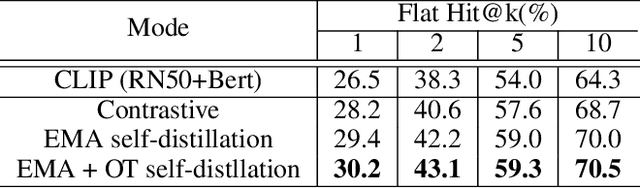
Traditional computer vision models are trained to predict a fixed set of predefined categories. Recently, natural language has been shown to be a broader and richer source of supervision that provides finer descriptions to visual concepts than supervised "gold" labels. Previous works, such as CLIP, use InfoNCE loss to train a model to predict the pairing between images and text captions. CLIP, however, is data hungry and requires more than 400M image-text pairs for training. The inefficiency can be partially attributed to the fact that the image-text pairs are noisy. To address this, we propose OTTER (Optimal TransporT distillation for Efficient zero-shot Recognition), which uses online entropic optimal transport to find a soft image-text match as labels for contrastive learning. Based on pretrained image and text encoders, models trained with OTTER achieve strong performance with only 3M image text pairs. Compared with InfoNCE loss, label smoothing, and knowledge distillation, OTTER consistently outperforms these baselines in zero shot evaluation on Google Open Images (19,958 classes) and multi-labeled ImageNet 10K (10032 classes) from Tencent ML-Images. Over 42 evaluations on 7 different dataset/architecture settings x 6 metrics, OTTER outperforms (32) or ties (2) all baselines in 34 of them.
Data-Efficient Language-Supervised Zero-Shot Learning with Self-Distillation
Apr 18, 2021

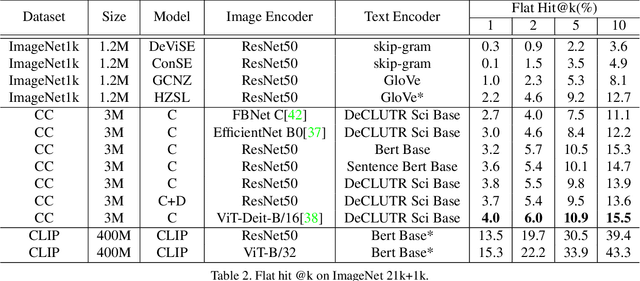
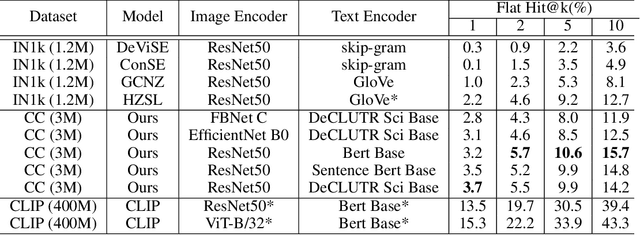
Traditional computer vision models are trained to predict a fixed set of predefined categories. Recently, natural language has been shown to be a broader and richer source of supervision that provides finer descriptions to visual concepts than supervised "gold" labels. Previous works, such as CLIP, use a simple pretraining task of predicting the pairings between images and text captions. CLIP, however, is data hungry and requires more than 400M image text pairs for training. We propose a data-efficient contrastive distillation method that uses soft labels to learn from noisy image-text pairs. Our model transfers knowledge from pretrained image and sentence encoders and achieves strong performance with only 3M image text pairs, 133x smaller than CLIP. Our method exceeds the previous SoTA of general zero-shot learning on ImageNet 21k+1k by 73% relatively with a ResNet50 image encoder and DeCLUTR text encoder. We also beat CLIP by 10.5% relatively on zero-shot evaluation on Google Open Images (19,958 classes).
Pay Attention to Convolution Filters: Towards Fast and Accurate Fine-Grained Transfer Learning
Jun 12, 2019
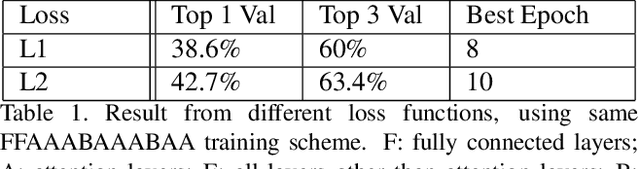
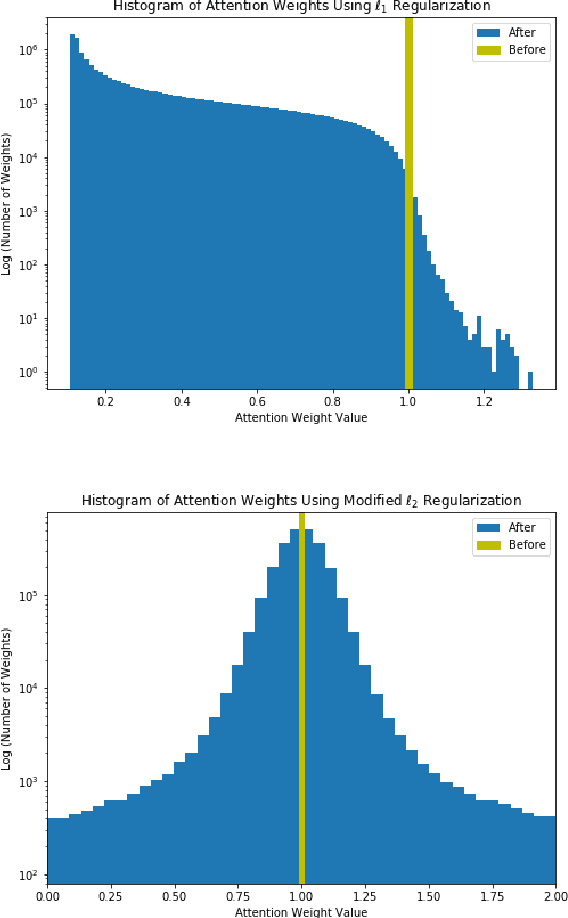
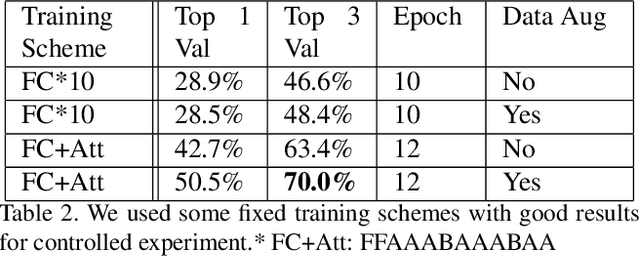
We propose an efficient transfer learning method for adapting ImageNet pre-trained Convolutional Neural Network (CNN) to fine-grained image classification task. Conventional transfer learning methods typically face the trade-off between training time and accuracy. By adding "attention module" to each convolutional filters of the pre-trained network, we are able to rank and adjust the importance of each convolutional signal in an end-to-end pipeline. In this report, we show our method can adapt a pre-trianed ResNet50 for a fine-grained transfer learning task within few epochs and achieve accuracy above conventional transfer learning methods and close to models trained from scratch. Our model also offer interpretable result because the rank of the convolutional signal shows which convolution channels are utilized and amplified to achieve better classification result, as well as which signal should be treated as noise for the specific transfer learning task, which could be pruned to lower model size.