 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraditional Chinese Medicine Case Analysis System for High-Level Semantic Abstraction: Optimized with Prompt and RAG
Nov 23, 2024


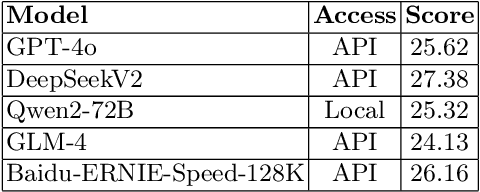
This paper details a technical plan for building a clinical case database for Traditional Chinese Medicine (TCM) using web scraping. Leveraging multiple platforms, including 360doc, we gathered over 5,000 TCM clinical cases, performed data cleaning, and structured the dataset with crucial fields such as patient details, pathogenesis, syndromes, and annotations. Using the $Baidu\_ERNIE\_Speed\_128K$ API, we removed redundant information and generated the final answers through the $DeepSeekv2$ API, outputting results in standard JSON format. We optimized data recall with RAG and rerank techniques during retrieval and developed a hybrid matching scheme. By combining two-stage retrieval method with keyword matching via Jieba, we significantly enhanced the accuracy of model outputs.