 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Adaptivity Barrier in Batched Nonparametric Bandits: Sharp Characterization of the Price of Unknown Margin
Nov 05, 2025We study batched nonparametric contextual bandits under a margin condition when the margin parameter $\alpha$ is unknown. To capture the statistical price of this ignorance, we introduce the regret inflation criterion, defined as the ratio between the regret of an adaptive algorithm and that of an oracle knowing $\alpha$. We show that the optimal regret inflation grows polynomial with the horizon $T$, with exponent precisely given by the value of a convex optimization problem involving the dimension, smoothness, and batch budget. Moreover, the minimizers of this optimization problem directly prescribe the batch allocation and exploration strategy of a rate-optimal algorithm. Building on this principle, we develop RoBIN (RObust batched algorithm with adaptive BINning), which achieves the optimal regret inflation up to logarithmic factors. These results reveal a new adaptivity barrier: under batching, adaptation to an unknown margin parameter inevitably incurs a polynomial penalty, sharply characterized by a variational problem. Remarkably, this barrier vanishes when the number of batches exceeds $\log \log T$; with only a doubly logarithmic number of updates, one can recover the oracle regret rate up to polylogarithmic factors.
Semi-supervised learning for linear extremile regression
Jul 02, 2025Extremile regression, as a least squares analog of quantile regression, is potentially useful tool for modeling and understanding the extreme tails of a distribution. However, existing extremile regression methods, as nonparametric approaches, may face challenges in high-dimensional settings due to data sparsity, computational inefficiency, and the risk of overfitting. While linear regression serves as the foundation for many other statistical and machine learning models due to its simplicity, interpretability, and relatively easy implementation, particularly in high-dimensional settings, this paper introduces a novel definition of linear extremile regression along with an accompanying estimation methodology. The regression coefficient estimators of this method achieve $\sqrt{n}$-consistency, which nonparametric extremile regression may not provide. In particular, while semi-supervised learning can leverage unlabeled data to make more accurate predictions and avoid overfitting to small labeled datasets in high-dimensional spaces, we propose a semi-supervised learning approach to enhance estimation efficiency, even when the specified linear extremile regression model may be misspecified. Both simulation studies and real data analyses demonstrate the finite-sample performance of our proposed methods.
Batched Nonparametric Contextual Bandits
Feb 27, 2024


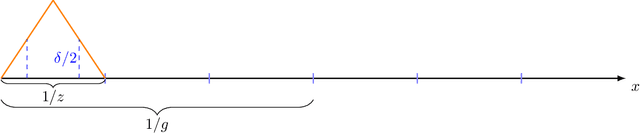
We study nonparametric contextual bandits under batch constraints, where the expected reward for each action is modeled as a smooth function of covariates, and the policy updates are made at the end of each batch of observations. We establish a minimax regret lower bound for this setting and propose Batched Successive Elimination with Dynamic Binning (BaSEDB) that achieves optimal regret (up to logarithmic factors). In essence, BaSEDB dynamically splits the covariate space into smaller bins, carefully aligning their widths with the batch size. We also show the suboptimality of static binning under batch constraints, highlighting the necessity of dynamic binning. Additionally, our results suggest that a nearly constant number of policy updates can attain optimal regret in the fully online setting.