 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn empirical evaluation of imbalanced data strategies from a practitioner's point of view
Oct 16, 2018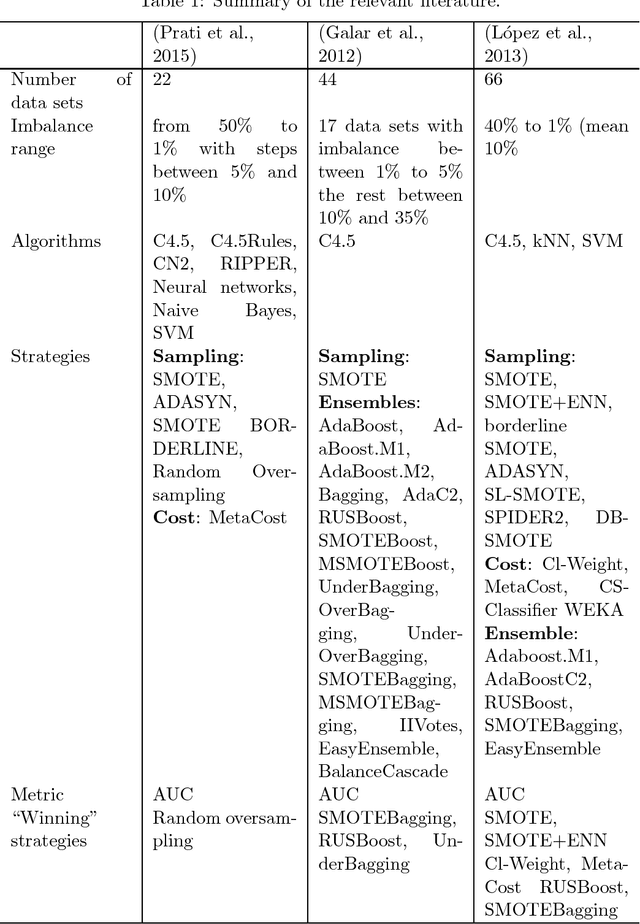
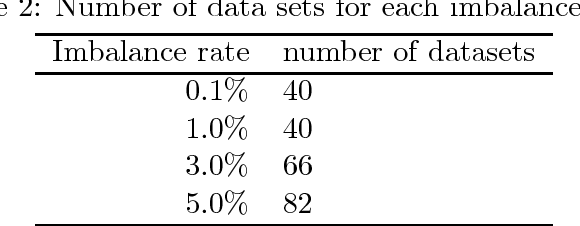
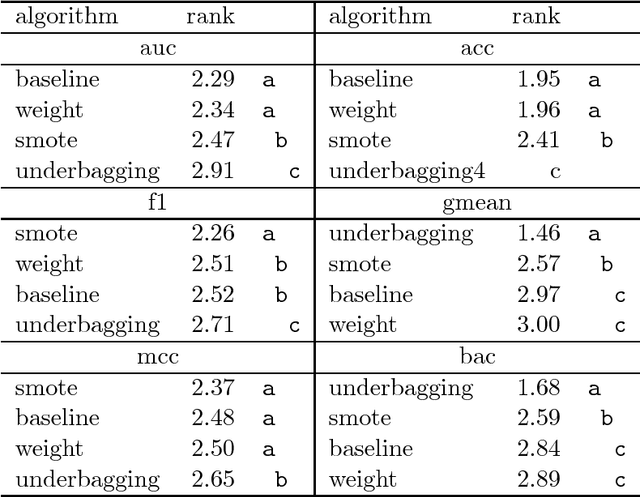
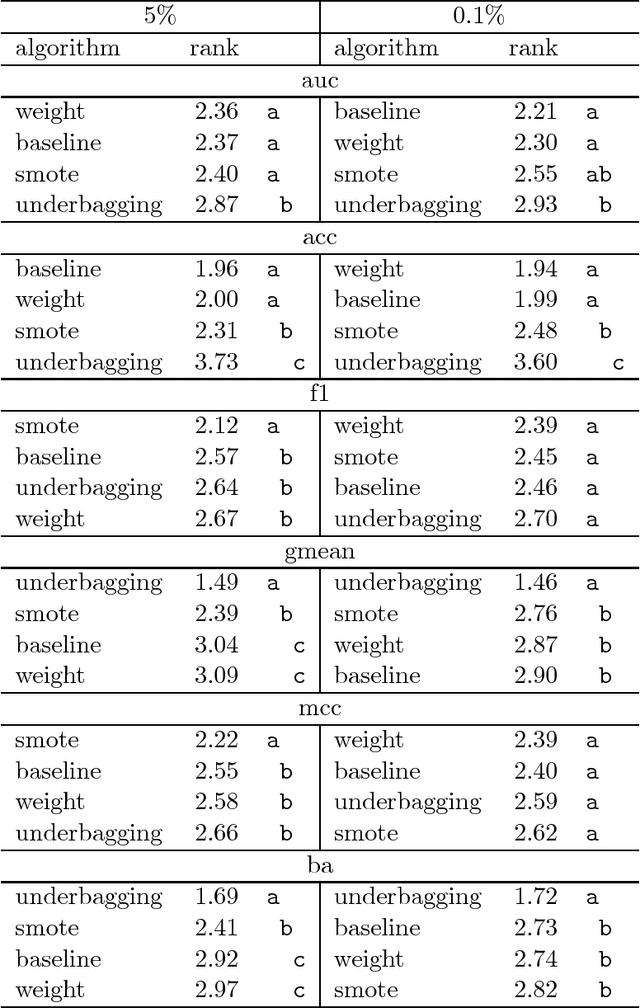
This research tested the following well known strategies to deal with binary imbalanced data on 82 different real life data sets (sampled to imbalance rates of 5%, 3%, 1%, and 0.1%): class weight, SMOTE, Underbagging, and a baseline (just the base classifier). As base classifiers we used SVM with RBF kernel, random forests, and gradient boosting machines and we measured the quality of the resulting classifier using 6 different metrics (Area under the curve, Accuracy, F-measure, G-mean, Matthew's correlation coefficient and Balanced accuracy). The best strategy strongly depends on the metric used to measure the quality of the classifier. For AUC and accuracy class weight and the baseline perform better; for F-measure and MCC, SMOTE performs better; and for G-mean and balanced accuracy, underbagging.