 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRAUDGUESS: Spotting and Explaining New Types of Fraud in Million-Scale Financial Data
Sep 19, 2025Given a set of financial transactions (who buys from whom, when, and for how much), as well as prior information from buyers and sellers, how can we find fraudulent transactions? If we have labels for some transactions for known types of fraud, we can build a classifier. However, we also want to find new types of fraud, still unknown to the domain experts ('Detection'). Moreover, we also want to provide evidence to experts that supports our opinion ('Justification'). In this paper, we propose FRAUDGUESS, to achieve two goals: (a) for 'Detection', it spots new types of fraud as micro-clusters in a carefully designed feature space; (b) for 'Justification', it uses visualization and heatmaps for evidence, as well as an interactive dashboard for deep dives. FRAUDGUESS is used in real life and is currently considered for deployment in an Anonymous Financial Institution (AFI). Thus, we also present the three new behaviors that FRAUDGUESS discovered in a real, million-scale financial dataset. Two of these behaviors are deemed fraudulent or suspicious by domain experts, catching hundreds of fraudulent transactions that would otherwise go un-noticed.
McCatch: Scalable Microcluster Detection in Dimensional and Nondimensional Datasets
Mar 12, 2024



How could we have an outlier detector that works even with nondimensional data, and ranks together both singleton microclusters ('one-off' outliers) and nonsingleton microclusters by their anomaly scores? How to obtain scores that are principled in one scalable and 'hands-off' manner? Microclusters of outliers indicate coalition or repetition in fraud activities, etc.; their identification is thus highly desirable. This paper presents McCatch: a new algorithm that detects microclusters by leveraging our proposed 'Oracle' plot (1NN Distance versus Group 1NN Distance). We study 31 real and synthetic datasets with up to 1M data elements to show that McCatch is the only method that answers both of the questions above; and, it outperforms 11 other methods, especially when the data has nonsingleton microclusters or is nondimensional. We also showcase McCatch's ability to detect meaningful microclusters in graphs, fingerprints, logs of network connections, text data, and satellite imagery. For example, it found a 30-elements microcluster of confirmed 'Denial of Service' attacks in the network logs, taking only ~3 minutes for 222K data elements on a stock desktop.
C-AllOut: Catching & Calling Outliers by Type
Oct 13, 2021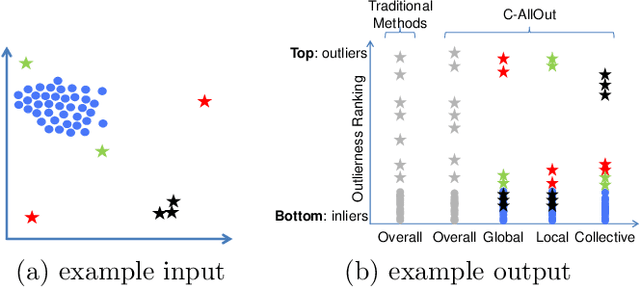
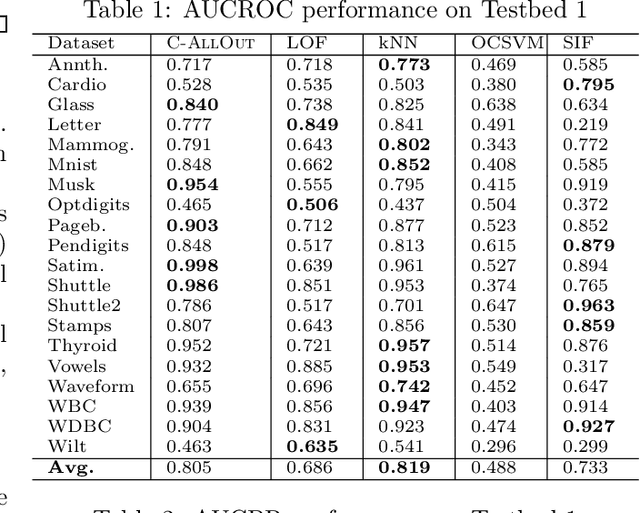
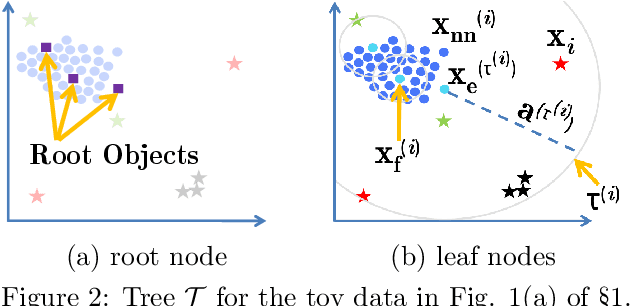
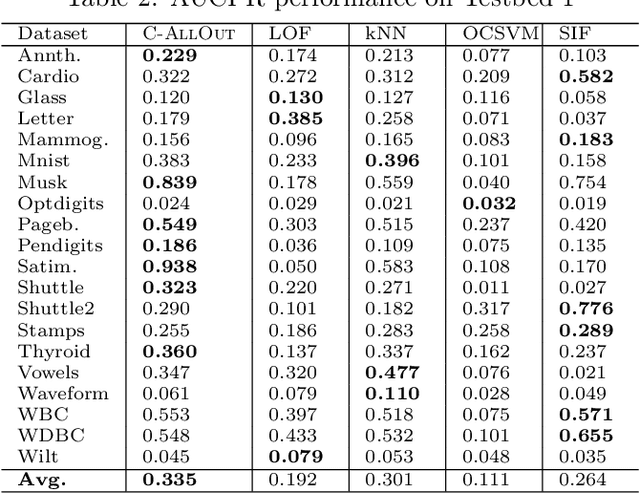
Given an unlabeled dataset, wherein we have access only to pairwise similarities (or distances), how can we effectively (1) detect outliers, and (2) annotate/tag the outliers by type? Outlier detection has a large literature, yet we find a key gap in the field: to our knowledge, no existing work addresses the outlier annotation problem. Outliers are broadly classified into 3 types, representing distinct patterns that could be valuable to analysts: (a) global outliers are severe yet isolate cases that do not repeat, e.g., a data collection error; (b) local outliers diverge from their peers within a context, e.g., a particularly short basketball player; and (c) collective outliers are isolated micro-clusters that may indicate coalition or repetitions, e.g., frauds that exploit the same loophole. This paper presents C-AllOut: a novel and effective outlier detector that annotates outliers by type. It is parameter-free and scalable, besides working only with pairwise similarities (or distances) when it is needed. We show that C-AllOut achieves on par or significantly better performance than state-of-the-art detectors when spotting outliers regardless of their type. It is also highly effective in annotating outliers of particular types, a task that none of the baselines can perform.