 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversary Aware Continual Learning
Apr 27, 2023



Class incremental learning approaches are useful as they help the model to learn new information (classes) sequentially, while also retaining the previously acquired information (classes). However, it has been shown that such approaches are extremely vulnerable to the adversarial backdoor attacks, where an intelligent adversary can introduce small amount of misinformation to the model in the form of imperceptible backdoor pattern during training to cause deliberate forgetting of a specific task or class at test time. In this work, we propose a novel defensive framework to counter such an insidious attack where, we use the attacker's primary strength-hiding the backdoor pattern by making it imperceptible to humans-against it, and propose to learn a perceptible (stronger) pattern (also during the training) that can overpower the attacker's imperceptible (weaker) pattern. We demonstrate the effectiveness of the proposed defensive mechanism through various commonly used Replay-based (both generative and exact replay-based) class incremental learning algorithms using continual learning benchmark variants of CIFAR-10, CIFAR-100, and MNIST datasets. Most noteworthy, our proposed defensive framework does not assume that the attacker's target task and target class is known to the defender. The defender is also unaware of the shape, size, and location of the attacker's pattern. We show that our proposed defensive framework considerably improves the performance of class incremental learning algorithms with no knowledge of the attacker's target task, attacker's target class, and attacker's imperceptible pattern. We term our defensive framework as Adversary Aware Continual Learning (AACL).
Contributor-Aware Defenses Against Adversarial Backdoor Attacks
May 28, 2022
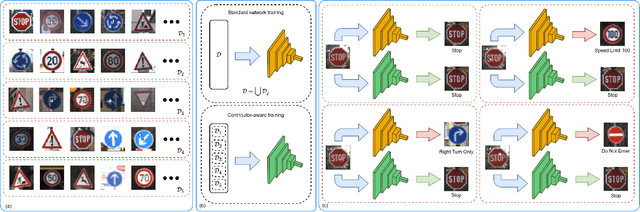
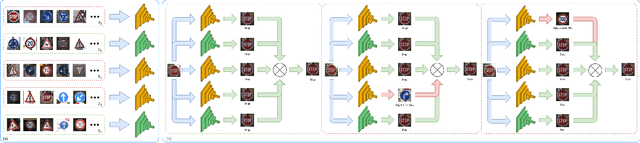
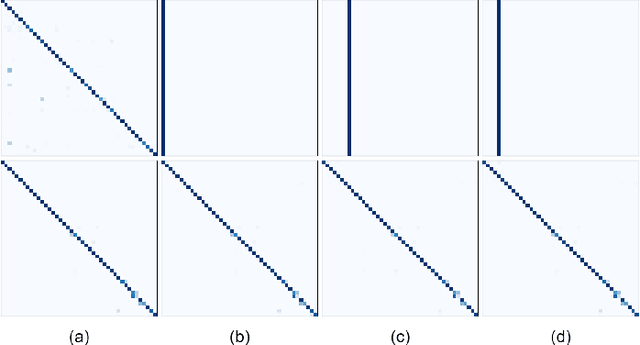
Deep neural networks for image classification are well-known to be vulnerable to adversarial attacks. One such attack that has garnered recent attention is the adversarial backdoor attack, which has demonstrated the capability to perform targeted misclassification of specific examples. In particular, backdoor attacks attempt to force a model to learn spurious relations between backdoor trigger patterns and false labels. In response to this threat, numerous defensive measures have been proposed; however, defenses against backdoor attacks focus on backdoor pattern detection, which may be unreliable against novel or unexpected types of backdoor pattern designs. We introduce a novel re-contextualization of the adversarial setting, where the presence of an adversary implicitly admits the existence of multiple database contributors. Then, under the mild assumption of contributor awareness, it becomes possible to exploit this knowledge to defend against backdoor attacks by destroying the false label associations. We propose a contributor-aware universal defensive framework for learning in the presence of multiple, potentially adversarial data sources that utilizes semi-supervised ensembles and learning from crowds to filter the false labels produced by adversarial triggers. Importantly, this defensive strategy is agnostic to backdoor pattern design, as it functions without needing -- or even attempting -- to perform either adversary identification or backdoor pattern detection during either training or inference. Our empirical studies demonstrate the robustness of the proposed framework against adversarial backdoor attacks from multiple simultaneous adversaries.
False Memory Formation in Continual Learners Through Imperceptible Backdoor Trigger
Feb 09, 2022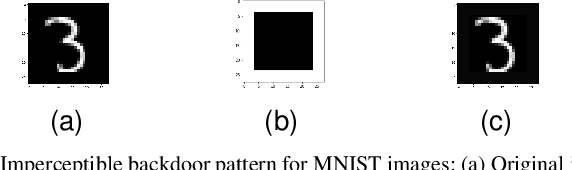
In this brief, we show that sequentially learning new information presented to a continual (incremental) learning model introduces new security risks: an intelligent adversary can introduce small amount of misinformation to the model during training to cause deliberate forgetting of a specific task or class at test time, thus creating "false memory" about that task. We demonstrate such an adversary's ability to assume control of the model by injecting "backdoor" attack samples to commonly used generative replay and regularization based continual learning approaches using continual learning benchmark variants of MNIST, as well as the more challenging SVHN and CIFAR 10 datasets. Perhaps most damaging, we show this vulnerability to be very acute and exceptionally effective: the backdoor pattern in our attack model can be imperceptible to human eye, can be provided at any point in time, can be added into the training data of even a single possibly unrelated task and can be achieved with as few as just 1\% of total training dataset of a single task.
Rethinking Noisy Label Models: Labeler-Dependent Noise with Adversarial Awareness
Jun 05, 2021



Most studies on learning from noisy labels rely on unrealistic models of i.i.d. label noise, such as class-conditional transition matrices. More recent work on instance-dependent noise models are more realistic, but assume a single generative process for label noise across the entire dataset. We propose a more principled model of label noise that generalizes instance-dependent noise to multiple labelers, based on the observation that modern datasets are typically annotated using distributed crowdsourcing methods. Under our labeler-dependent model, label noise manifests itself under two modalities: natural error of good-faith labelers, and adversarial labels provided by malicious actors. We present two adversarial attack vectors that more accurately reflect the label noise that may be encountered in real-world settings, and demonstrate that under our multimodal noisy labels model, state-of-the-art approaches for learning from noisy labels are defeated by adversarial label attacks. Finally, we propose a multi-stage, labeler-aware, model-agnostic framework that reliably filters noisy labels by leveraging knowledge about which data partitions were labeled by which labeler, and show that our proposed framework remains robust even in the presence of extreme adversarial label noise.
Adversarial Targeted Forgetting in Regularization and Generative Based Continual Learning Models
Feb 16, 2021

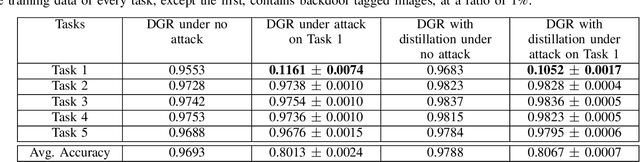
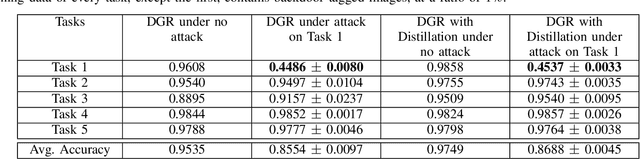
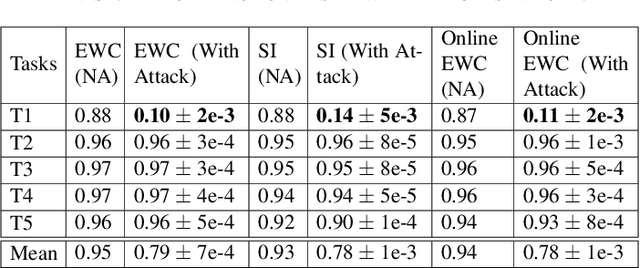
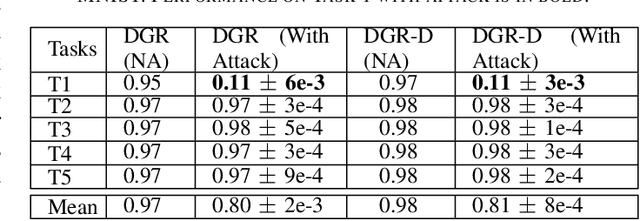
Continual (or "incremental") learning approaches are employed when additional knowledge or tasks need to be learned from subsequent batches or from streaming data. However these approaches are typically adversary agnostic, i.e., they do not consider the possibility of a malicious attack. In our prior work, we explored the vulnerabilities of Elastic Weight Consolidation (EWC) to the perceptible misinformation. We now explore the vulnerabilities of other regularization-based as well as generative replay-based continual learning algorithms, and also extend the attack to imperceptible misinformation. We show that an intelligent adversary can take advantage of a continual learning algorithm's capabilities of retaining existing knowledge over time, and force it to learn and retain deliberately introduced misinformation. To demonstrate this vulnerability, we inject backdoor attack samples into the training data. These attack samples constitute the misinformation, allowing the attacker to capture control of the model at test time. We evaluate the extent of this vulnerability on both rotated and split benchmark variants of the MNIST dataset under two important domain and class incremental learning scenarios. We show that the adversary can create a "false memory" about any task by inserting carefully-designed backdoor samples to the test instances of that task thereby controlling the amount of forgetting of any task of its choosing. Perhaps most importantly, we show this vulnerability to be very acute and damaging: the model memory can be easily compromised with the addition of backdoor samples into as little as 1\% of the training data, even when the misinformation is imperceptible to human eye.
OpinionRank: Extracting Ground Truth Labels from Unreliable Expert Opinions with Graph-Based Spectral Ranking
Feb 11, 2021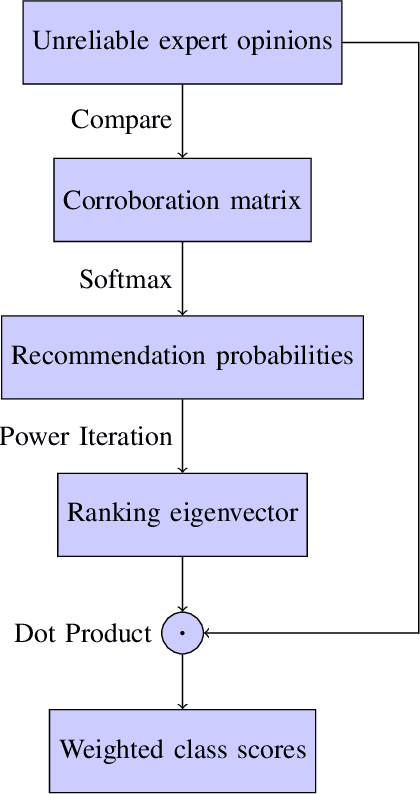
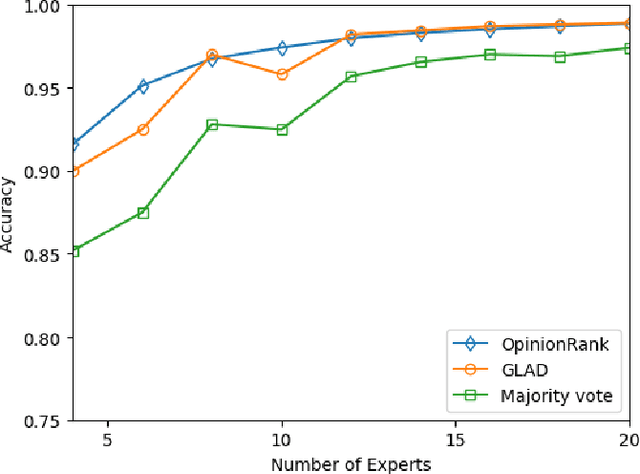
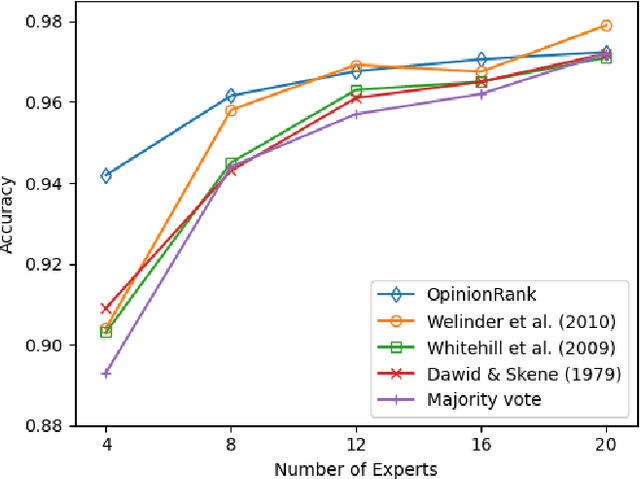
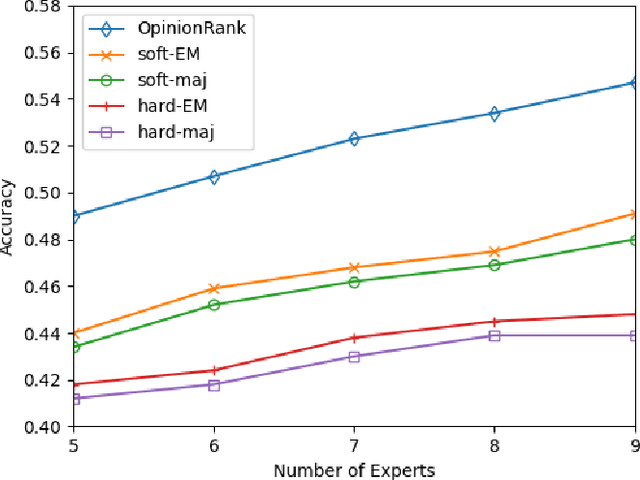
As larger and more comprehensive datasets become standard in contemporary machine learning, it becomes increasingly more difficult to obtain reliable, trustworthy label information with which to train sophisticated models. To address this problem, crowdsourcing has emerged as a popular, inexpensive, and efficient data mining solution for performing distributed label collection. However, crowdsourced annotations are inherently untrustworthy, as the labels are provided by anonymous volunteers who may have varying, unreliable expertise. Worse yet, some participants on commonly used platforms such as Amazon Mechanical Turk may be adversarial, and provide intentionally incorrect label information without the end user's knowledge. We discuss three conventional models of the label generation process, describing their parameterizations and the model-based approaches used to solve them. We then propose OpinionRank, a model-free, interpretable, graph-based spectral algorithm for integrating crowdsourced annotations into reliable labels for performing supervised or semi-supervised learning. Our experiments show that OpinionRank performs favorably when compared against more highly parameterized algorithms. We also show that OpinionRank is scalable to very large datasets and numbers of label sources, and requires considerably less computational resources than previous approaches.
Comparative Analysis of Extreme Verification Latency Learning Algorithms
Nov 26, 2020

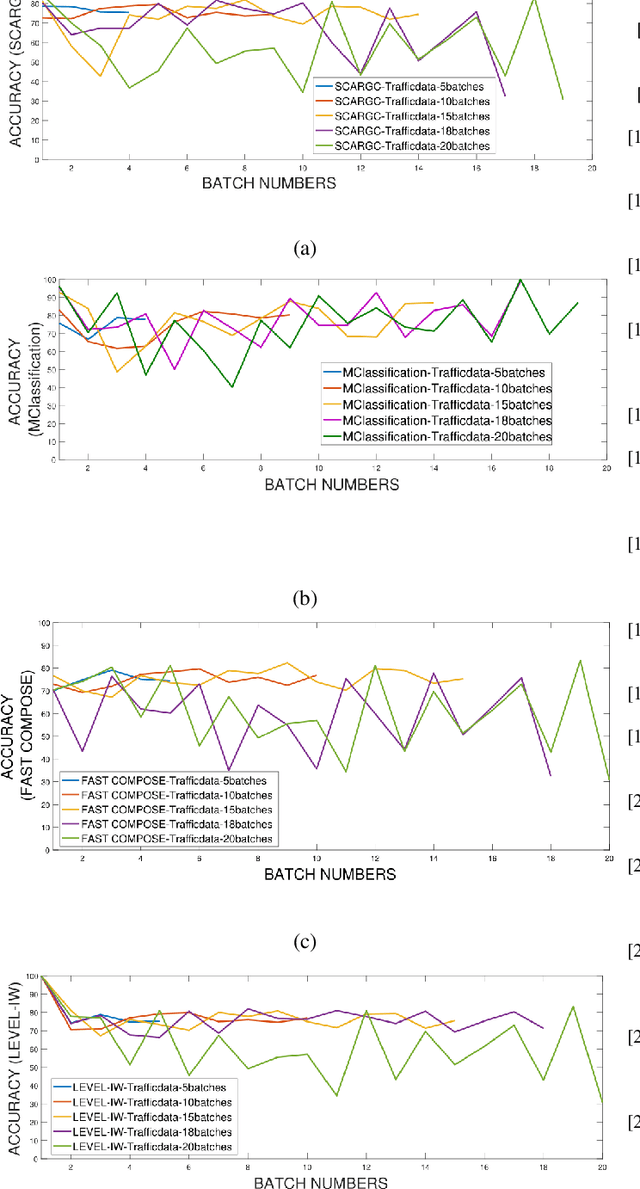
One of the more challenging real-world problems in computational intelligence is to learn from non-stationary streaming data, also known as concept drift. Perhaps even a more challenging version of this scenario is when -- following a small set of initial labeled data -- the data stream consists of unlabeled data only. Such a scenario is typically referred to as learning in initially labeled nonstationary environment, or simply as extreme verification latency (EVL). Because of the very challenging nature of the problem, very few algorithms have been proposed in the literature up to date. This work is a very first effort to provide a review of some of the existing algorithms (important/prominent) in this field to the research community. More specifically, this paper is a comprehensive survey and comparative analysis of some of the EVL algorithms to point out the weaknesses and strengths of different approaches from three different perspectives: classification accuracy, computational complexity and parameter sensitivity using several synthetic and real world datasets.
Targeted Forgetting and False Memory Formation in Continual Learners through Adversarial Backdoor Attacks
Feb 17, 2020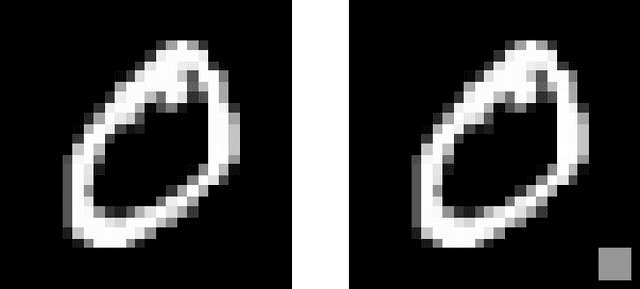



Artificial neural networks are well-known to be susceptible to catastrophic forgetting when continually learning from sequences of tasks. Various continual (or "incremental") learning approaches have been proposed to avoid catastrophic forgetting, but they are typically adversary agnostic, i.e., they do not consider the possibility of a malicious attack. In this effort, we explore the vulnerability of Elastic Weight Consolidation (EWC), a popular continual learning algorithm for avoiding catastrophic forgetting. We show that an intelligent adversary can bypass the EWC's defenses, and instead cause gradual and deliberate forgetting by introducing small amounts of misinformation to the model during training. We demonstrate such an adversary's ability to assume control of the model via injection of "backdoor" attack samples on both permuted and split benchmark variants of the MNIST dataset. Importantly, once the model has learned the adversarial misinformation, the adversary can then control the amount of forgetting of any task. Equivalently, the malicious actor can create a "false memory" about any task by inserting carefully-designed backdoor samples to any fraction of the test instances of that task. Perhaps most damaging, we show this vulnerability to be very acute; neural network memory can be easily compromised with the addition of backdoor samples into as little as 1% of the training data of even a single task.
Attack Strength vs. Detectability Dilemma in Adversarial Machine Learning
Feb 20, 2018



As the prevalence and everyday use of machine learning algorithms, along with our reliance on these algorithms grow dramatically, so do the efforts to attack and undermine these algorithms with malicious intent, resulting in a growing interest in adversarial machine learning. A number of approaches have been developed that can render a machine learning algorithm ineffective through poisoning or other types of attacks. Most attack algorithms typically use sophisticated optimization approaches, whose objective function is designed to cause maximum damage with respect to accuracy and performance of the algorithm with respect to some task. In this effort, we show that while such an objective function is indeed brutally effective in causing maximum damage on an embedded feature selection task, it often results in an attack mechanism that can be easily detected with an embarrassingly simple novelty or outlier detection algorithm. We then propose an equally simple yet elegant solution by adding a regularization term to the attacker's objective function that penalizes outlying attack points.