 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA generalized machine learning framework for brittle crack problems using transfer learning and graph neural networks
Nov 22, 2022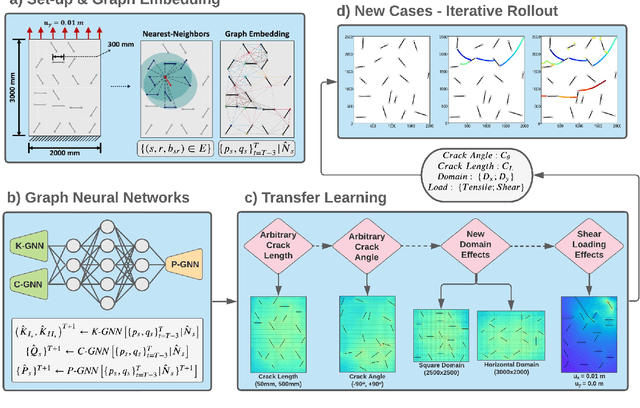
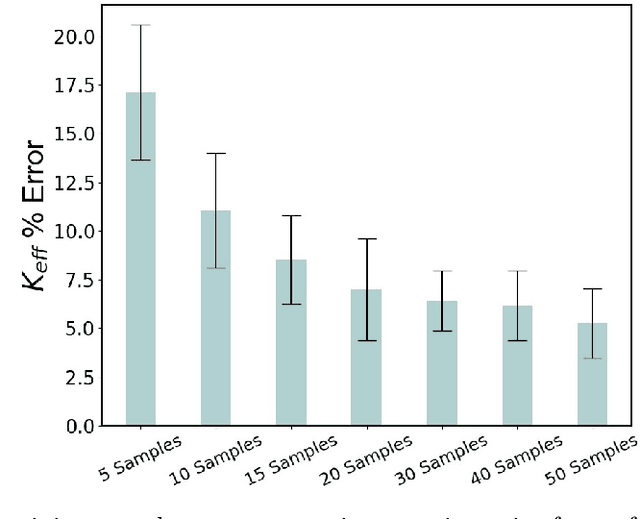
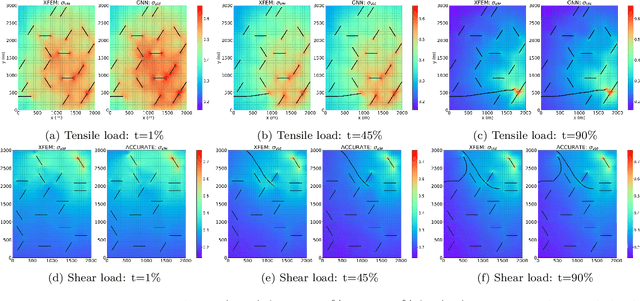
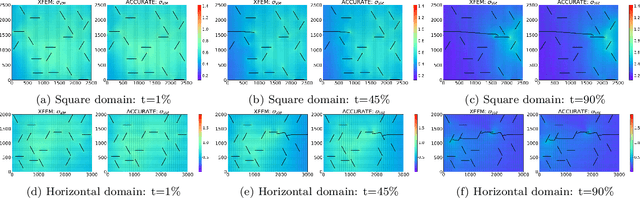
Despite their recent success, machine learning (ML) models such as graph neural networks (GNNs), suffer from drawbacks such as the need for large training datasets and poor performance for unseen cases. In this work, we use transfer learning (TL) approaches to circumvent the need for retraining with large datasets. We apply TL to an existing ML framework, trained to predict multiple crack propagation and stress evolution in brittle materials under Mode-I loading. The new framework, ACCelerated Universal fRAcTure Emulator (ACCURATE), is generalized to a variety of crack problems by using a sequence of TL update steps including (i) arbitrary crack lengths, (ii) arbitrary crack orientations, (iii) square domains, (iv) horizontal domains, and (v) shear loadings. We show that using small training datasets of 20 simulations for each TL update step, ACCURATE achieved high prediction accuracy in Mode-I and Mode-II stress intensity factors, and crack paths for these problems. %case studies (i) - (iv). We demonstrate ACCURATE's ability to predict crack growth and stress evolution with high accuracy for unseen cases involving the combination of new boundary dimensions with arbitrary crack lengths and crack orientations in both tensile and shear loading. We also demonstrate significantly accelerated simulation times of up to 2 orders of magnitude faster (200x) compared to an XFEM-based fracture model. The ACCURATE framework provides a universal computational fracture mechanics model that can be easily modified or extended in future work.
Shedding some light on Light Up with Artificial Intelligence
Jul 22, 2021
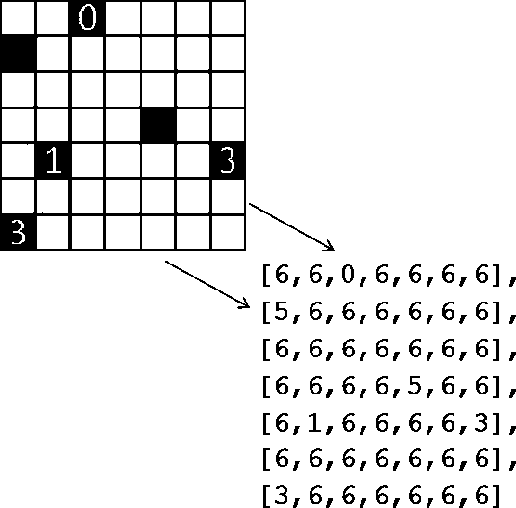
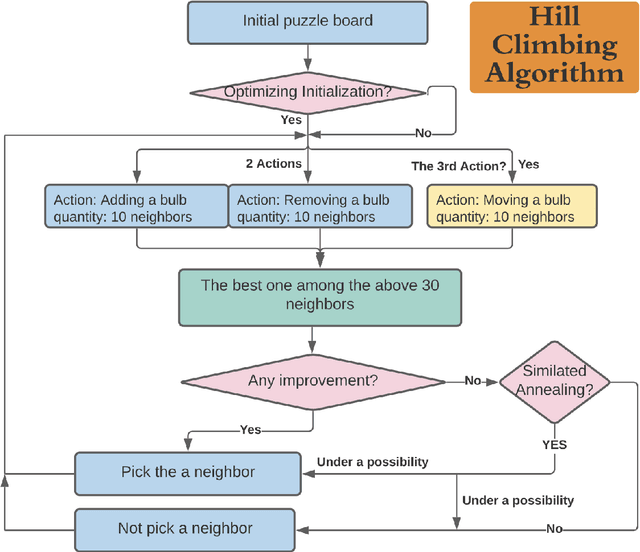

The Light-Up puzzle, also known as the AKARI puzzle, has never been solved using modern artificial intelligence (AI) methods. Currently, the most widely used computational technique to autonomously develop solutions involve evolution theory algorithms. This project is an effort to apply new AI techniques for solving the Light-up puzzle faster and more computationally efficient. The algorithms explored for producing optimal solutions include hill climbing, simulated annealing, feed-forward neural network (FNN), and convolutional neural network (CNN). Two algorithms were developed for hill climbing and simulated annealing using 2 actions (add and remove light bulb) versus 3 actions(add, remove, or move light-bulb to a different cell). Both hill climbing and simulated annealing algorithms showed a higher accuracy for the case of 3 actions. The simulated annealing showed to significantly outperform hill climbing, FNN, CNN, and an evolutionary theory algorithm achieving 100% accuracy in 30 unique board configurations. Lastly, while FNN and CNN algorithms showed low accuracies, computational times were significantly faster compared to the remaining algorithms. The GitHub repository for this project can be found at https://github.com/rperera12/AKARI-LightUp-GameSolver-with-DeepNeuralNetworks-and-HillClimb-or-SimulatedAnnealing.
Optimized and autonomous machine learning framework for characterizing pores, particles, grains and grain boundaries in microstructural images
Jan 16, 2021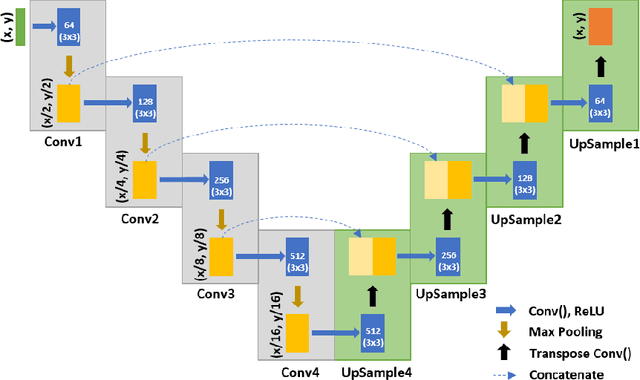
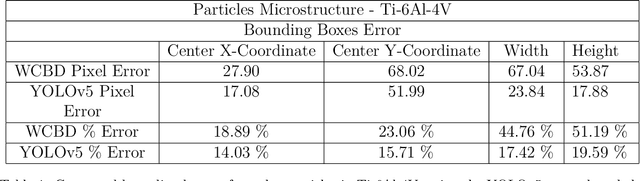
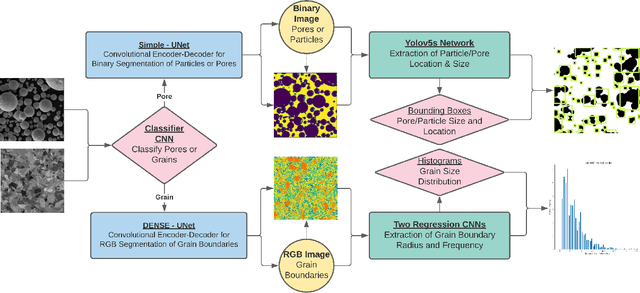
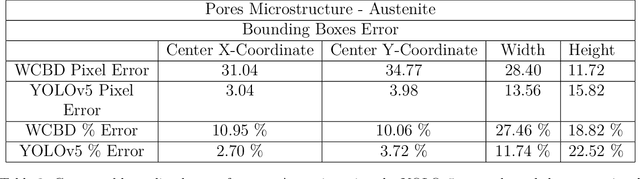
Additively manufactured metals exhibit heterogeneous microstructure which dictates their material and failure properties. Experimental microstructural characterization techniques generate a large amount of data that requires expensive computationally resources. In this work, an optimized machine learning (ML) framework is proposed to autonomously and efficiently characterize pores, particles, grains and grain boundaries (GBs) from a given microstructure image. First, using a classifier Convolutional Neural Network (CNN), defects such as pores, powder particles, or GBs were recognized from a given microstructure. Depending on the type of defect, two different processes were used. For powder particles or pores, binary segmentations were generated using an optimized Convolutional Encoder-Decoder Network (CEDN). The binary segmentations were used to used obtain particle and pore size and bounding boxes using an object detection ML network (YOLOv5). For GBs, another optimized CEDN was developed to generate RGB segmentation images, which were used to obtain grain size distribution using two regression CNNS. To optimize the RGB CEDN, the Deep Emulator Network SEarch (DENSE) method which employs the Covariance Matrix Adaptation - Evolution Strategy (CMA-ES) was implemented. The optimized RGB segmentation network showed a substantial reduction in training time and GPU usage compared to the unoptimized network, while maintaining high accuracy. Lastly, the proposed framework showed a significant improvement in analysis time when compared to conventional methods.