 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Irreproducibility in Deep Networks
Feb 21, 2021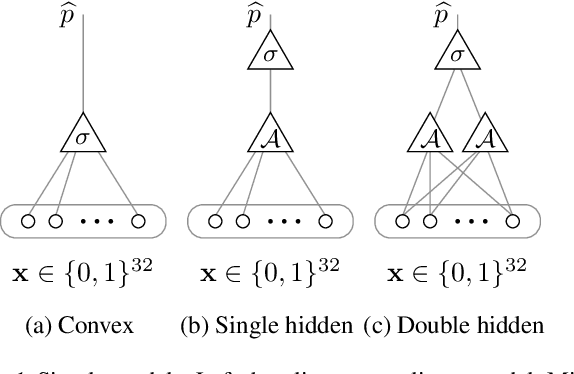
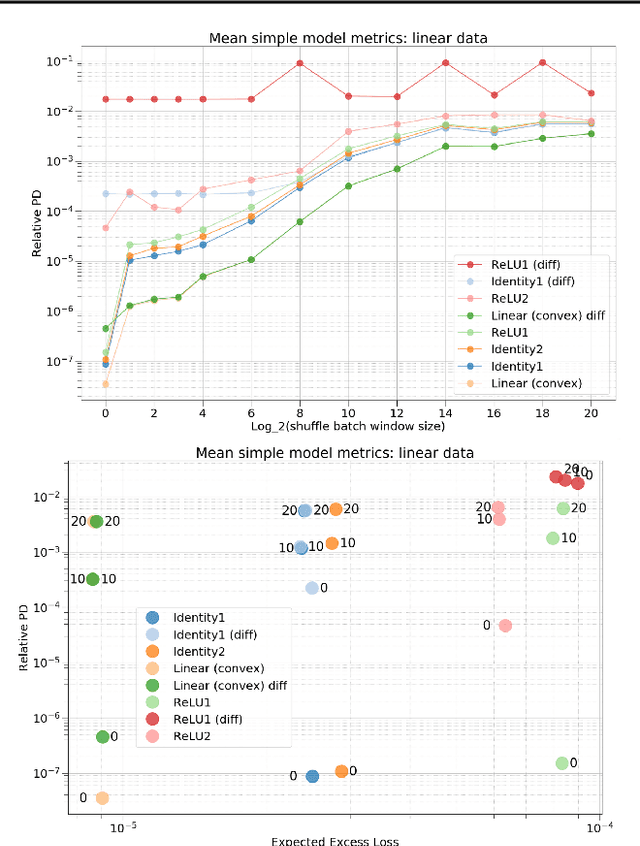


The success and superior performance of deep networks is spreading their popularity and use to an increasing number of applications. Very recent works, however, demonstrate that modern day deep networks suffer from irreproducibility (also referred to as nondeterminism or underspecification). Two or more models that are identical in architecture, structure, training hyper-parameters, and parameters, and that are trained on exactly the same training data, yield different predictions on individual previously unseen examples. Thus, a model that performs well on controlled test data, may perform in unexpected ways when deployed in the real world, whose data is expected to be similar to the test data. We study simple synthetic models and data to understand the origins of these problems. We show that even with a single nonlinearity and for very simple data and models, irreproducibility occurs. Our study demonstrates the effects of randomness in initialization, training data shuffling window size, and activation functions on prediction irreproducibility, even under very controlled synthetic data. While, as one would expect, randomness in initialization and in shuffling the training examples exacerbates the phenomenon, we show that model complexity and the choice of nonlinearity also play significant roles in making deep models irreproducible.