 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Consistency of the Bootstrap Approach for Support Vector Machines and Related Kernel Based Methods
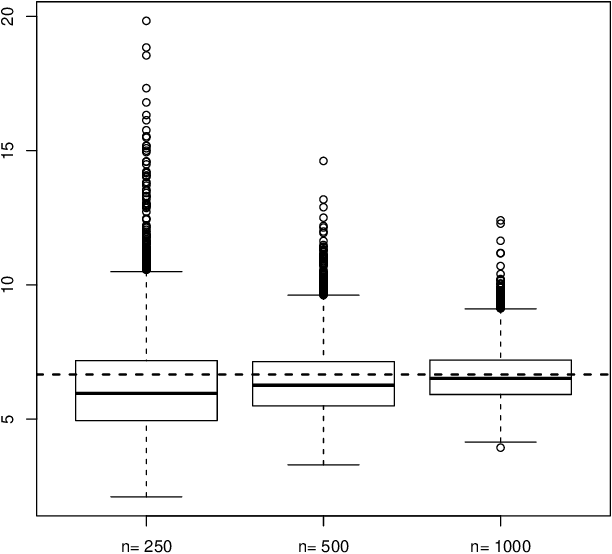
Jan 29, 2013It is shown that bootstrap approximations of support vector machines (SVMs) based on a general convex and smooth loss function and on a general kernel are consistent. This result is useful to approximate the unknown finite sample distribution of SVMs by the bootstrap approach.
Asymptotic Confidence Sets for General Nonparametric Regression and Classification by Regularized Kernel Methods
Mar 20, 2012


Regularized kernel methods such as, e.g., support vector machines and least-squares support vector regression constitute an important class of standard learning algorithms in machine learning. Theoretical investigations concerning asymptotic properties have manly focused on rates of convergence during the last years but there are only very few and limited (asymptotic) results on statistical inference so far. As this is a serious limitation for their use in mathematical statistics, the goal of the article is to fill this gap. Based on asymptotic normality of many of these methods, the article derives a strongly consistent estimator for the unknown covariance matrix of the limiting normal distribution. In this way, we obtain asymptotically correct confidence sets for $\psi(f_{P,\lambda_0})$ where $f_{P,\lambda_0}$ denotes the minimizer of the regularized risk in the reproducing kernel Hilbert space $H$ and $\psi:H\rightarrow\mathds{R}^m$ is any Hadamard-differentiable functional. Applications include (multivariate) pointwise confidence sets for values of $f_{P,\lambda_0}$ and confidence sets for gradients, integrals, and norms.
Estimation of scale functions to model heteroscedasticity by support vector machines
Nov 08, 2011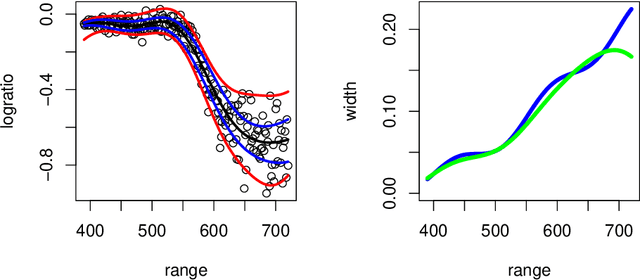
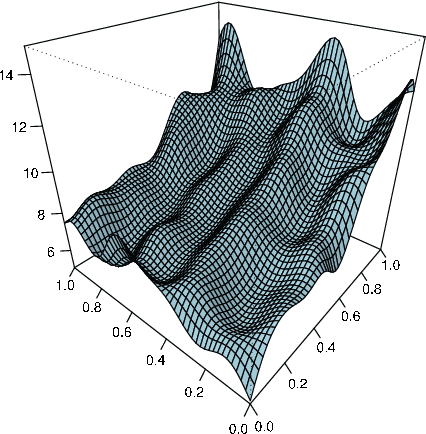
A main goal of regression is to derive statistical conclusions on the conditional distribution of the output variable Y given the input values x. Two of the most important characteristics of a single distribution are location and scale. Support vector machines (SVMs) are well established to estimate location functions like the conditional median or the conditional mean. We investigate the estimation of scale functions by SVMs when the conditional median is unknown, too. Estimation of scale functions is important e.g. to estimate the volatility in finance. We consider the median absolute deviation (MAD) and the interquantile range (IQR) as measures of scale. Our main result shows the consistency of MAD-type SVMs.
Qualitative Robustness of Support Vector Machines
Nov 03, 2011
Support vector machines have attracted much attention in theoretical and in applied statistics. Main topics of recent interest are consistency, learning rates and robustness. In this article, it is shown that support vector machines are qualitatively robust. Since support vector machines can be represented by a functional on the set of all probability measures, qualitative robustness is proven by showing that this functional is continuous with respect to the topology generated by weak convergence of probability measures. Combined with the existence and uniqueness of support vector machines, our results show that support vector machines are the solutions of a well-posed mathematical problem in Hadamard's sense.
Asymptotic Normality of Support Vector Machine Variants and Other Regularized Kernel Methods
Apr 12, 2011In nonparametric classification and regression problems, regularized kernel methods, in particular support vector machines, attract much attention in theoretical and in applied statistics. In an abstract sense, regularized kernel methods (simply called SVMs here) can be seen as regularized M-estimators for a parameter in a (typically infinite dimensional) reproducing kernel Hilbert space. For smooth loss functions, it is shown that the difference between the estimator, i.e.\ the empirical SVM, and the theoretical SVM is asymptotically normal with rate $\sqrt{n}$. That is, the standardized difference converges weakly to a Gaussian process in the reproducing kernel Hilbert space. As common in real applications, the choice of the regularization parameter may depend on the data. The proof is done by an application of the functional delta-method and by showing that the SVM-functional is suitably Hadamard-differentiable.
Support Vector Machines for Additive Models: Consistency and Robustness
Jul 23, 2010

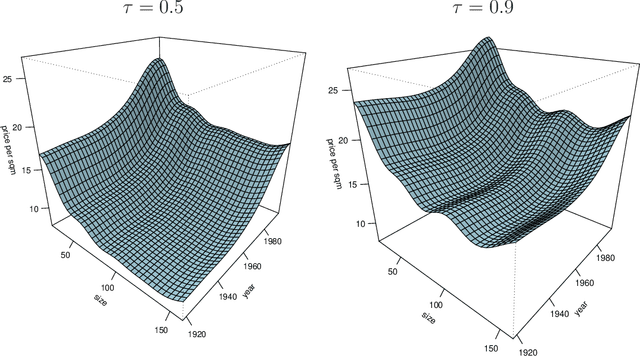
Support vector machines (SVMs) are special kernel based methods and belong to the most successful learning methods since more than a decade. SVMs can informally be described as a kind of regularized M-estimators for functions and have demonstrated their usefulness in many complicated real-life problems. During the last years a great part of the statistical research on SVMs has concentrated on the question how to design SVMs such that they are universally consistent and statistically robust for nonparametric classification or nonparametric regression purposes. In many applications, some qualitative prior knowledge of the distribution P or of the unknown function f to be estimated is present or the prediction function with a good interpretability is desired, such that a semiparametric model or an additive model is of interest. In this paper we mainly address the question how to design SVMs by choosing the reproducing kernel Hilbert space (RKHS) or its corresponding kernel to obtain consistent and statistically robust estimators in additive models. We give an explicit construction of kernels - and thus of their RKHSs - which leads in combination with a Lipschitz continuous loss function to consistent and statistically robust SMVs for additive models. Examples are quantile regression based on the pinball loss function, regression based on the epsilon-insensitive loss function, and classification based on the hinge loss function.