 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning for Transient Classification: From Simulations to Real Data and ZTF to LSST
Feb 25, 2025Machine learning has become essential for automated classification of astronomical transients, but current approaches face significant limitations: classifiers trained on simulations struggle with real data, models developed for one survey cannot be easily applied to another, and new surveys require prohibitively large amounts of labelled training data. These challenges are particularly pressing as we approach the era of the Vera Rubin Observatory's Legacy Survey of Space and Time (LSST), where existing classification models will need to be retrained using LSST observations. We demonstrate that transfer learning can overcome these challenges by repurposing existing models trained on either simulations or data from other surveys. Starting with a model trained on simulated Zwicky Transient Facility (ZTF) light curves, we show that transfer learning reduces the amount of labelled real ZTF transients needed by 75\% while maintaining equivalent performance to models trained from scratch. Similarly, when adapting ZTF models for LSST simulations, transfer learning achieves 95\% of the baseline performance while requiring only 30\% of the training data. These findings have significant implications for the early operations of LSST, suggesting that reliable automated classification will be possible soon after the survey begins, rather than waiting months or years to accumulate sufficient training data.
Worse than Zero-shot? A Fact-Checking Dataset for Evaluating the Robustness of RAG Against Misleading Retrievals
Feb 22, 2025Retrieval-augmented generation (RAG) has shown impressive capabilities in mitigating hallucinations in large language models (LLMs). However, LLMs struggle to handle misleading retrievals and often fail to maintain their own reasoning when exposed to conflicting or selectively-framed evidence, making them vulnerable to real-world misinformation. In such real-world retrieval scenarios, misleading and conflicting information is rampant, particularly in the political domain, where evidence is often selectively framed, incomplete, or polarized. However, existing RAG benchmarks largely assume a clean retrieval setting, where models succeed by accurately retrieving and generating answers from gold-standard documents. This assumption fails to align with real-world conditions, leading to an overestimation of RAG system performance. To bridge this gap, we introduce RAGuard, a fact-checking dataset designed to evaluate the robustness of RAG systems against misleading retrievals. Unlike prior benchmarks that rely on synthetic noise, our dataset constructs its retrieval corpus from Reddit discussions, capturing naturally occurring misinformation. It categorizes retrieved evidence into three types: supporting, misleading, and irrelevant, providing a realistic and challenging testbed for assessing how well RAG systems navigate different retrieval information. Our benchmark experiments reveal that when exposed to misleading retrievals, all tested LLM-powered RAG systems perform worse than their zero-shot baselines (i.e., no retrieval at all), highlighting their susceptibility to noisy environments. To the best of our knowledge, RAGuard is the first benchmark to systematically assess RAG robustness against misleading evidence. We expect this benchmark will drive future research toward improving RAG systems beyond idealized datasets, making them more reliable for real-world applications.
A Classifier-Based Approach to Multi-Class Anomaly Detection for Astronomical Transients
Mar 21, 2024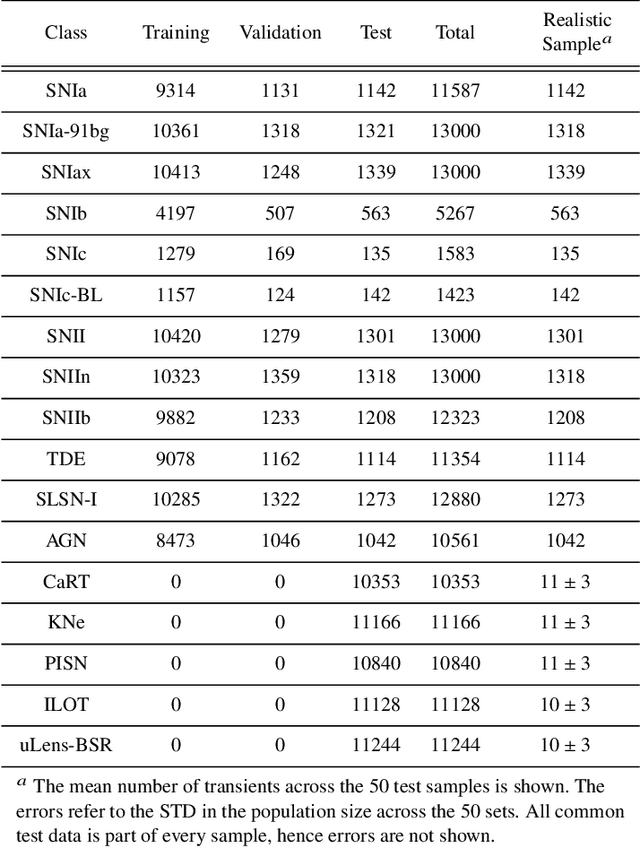
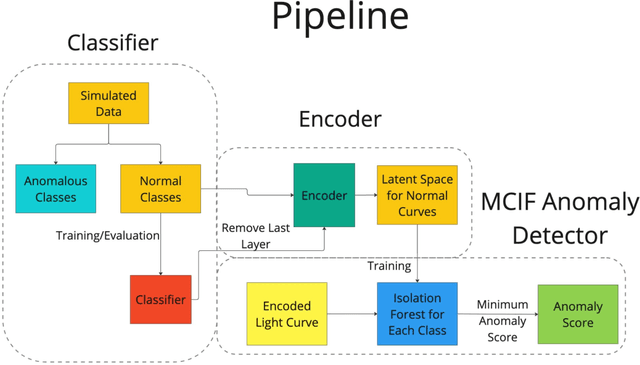
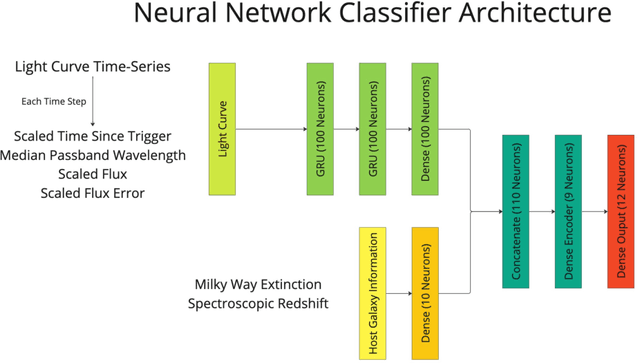
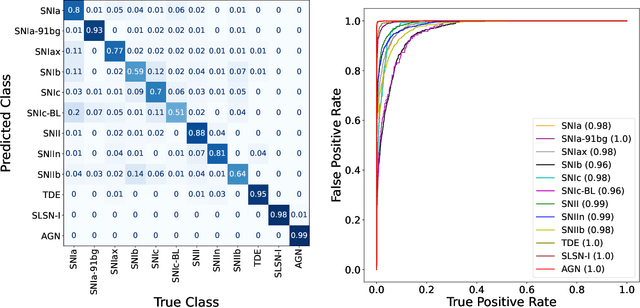
Automating real-time anomaly detection is essential for identifying rare transients in the era of large-scale astronomical surveys. Modern survey telescopes are generating tens of thousands of alerts per night, and future telescopes, such as the Vera C. Rubin Observatory, are projected to increase this number dramatically. Currently, most anomaly detection algorithms for astronomical transients rely either on hand-crafted features extracted from light curves or on features generated through unsupervised representation learning, which are then coupled with standard machine learning anomaly detection algorithms. In this work, we introduce an alternative approach to detecting anomalies: using the penultimate layer of a neural network classifier as the latent space for anomaly detection. We then propose a novel method, named Multi-Class Isolation Forests (MCIF), which trains separate isolation forests for each class to derive an anomaly score for a light curve from the latent space representation given by the classifier. This approach significantly outperforms a standard isolation forest. We also use a simpler input method for real-time transient classifiers which circumvents the need for interpolation in light curves and helps the neural network model inter-passband relationships and handle irregular sampling. Our anomaly detection pipeline identifies rare classes including kilonovae, pair-instability supernovae, and intermediate luminosity transients shortly after trigger on simulated Zwicky Transient Facility light curves. Using a sample of our simulations that matched the population of anomalies expected in nature (54 anomalies and 12,040 common transients), our method was able to discover $41\pm3$ anomalies (~75% recall) after following up the top 2000 (~15%) ranked transients. Our novel method shows that classifiers can be effectively repurposed for real-time anomaly detection.