 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Statistical Model of Word Rank Evolution
Jul 24, 2021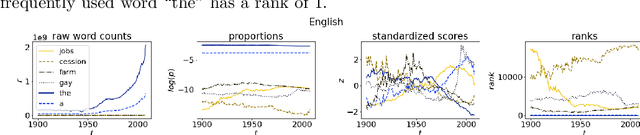
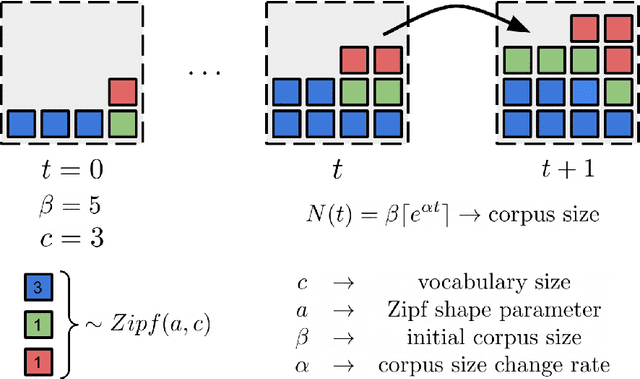
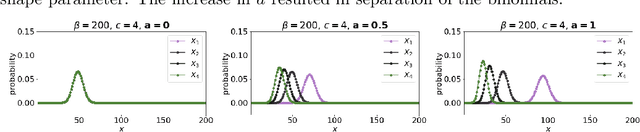
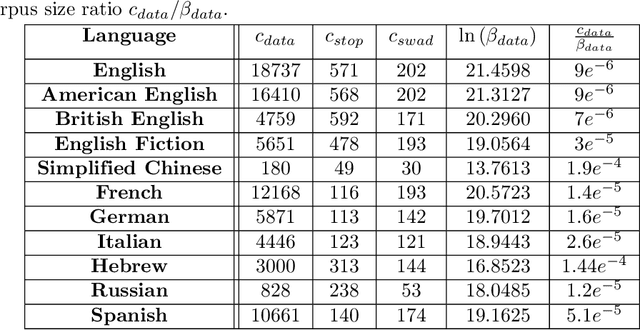
The availability of large linguistic data sets enables data-driven approaches to study linguistic change. This work explores the word rank dynamics of eight languages by investigating the Google Books corpus unigram frequency data set. We observed the rank changes of the unigrams from 1900 to 2008 and compared it to a Wright-Fisher inspired model that we developed for our analysis. The model simulates a neutral evolutionary process with the restriction of having no disappearing words. This work explains the mathematical framework of the model - written as a Markov Chain with multinomial transition probabilities - to show how frequencies of words change in time. From our observations in the data and our model, word rank stability shows two types of characteristics: (1) the increase/decrease in ranks are monotonic, or (2) the average rank stays the same. Based on our model, high-ranked words tend to be more stable while low-ranked words tend to be more volatile. Some words change in ranks in two ways: (a) by an accumulation of small increasing/decreasing rank changes in time and (b) by shocks of increase/decrease in ranks. Most of the stopwords and Swadesh words are observed to be stable in ranks across eight languages. These signatures suggest unigram frequencies in all languages have changed in a manner inconsistent with a purely neutral evolutionary process.
Dynamic Natural Language Processing with Recurrence Quantification Analysis
Mar 19, 2018

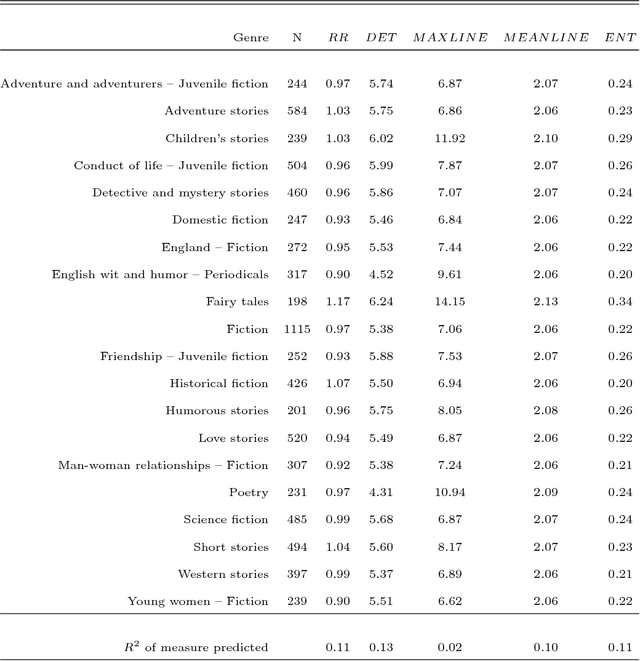
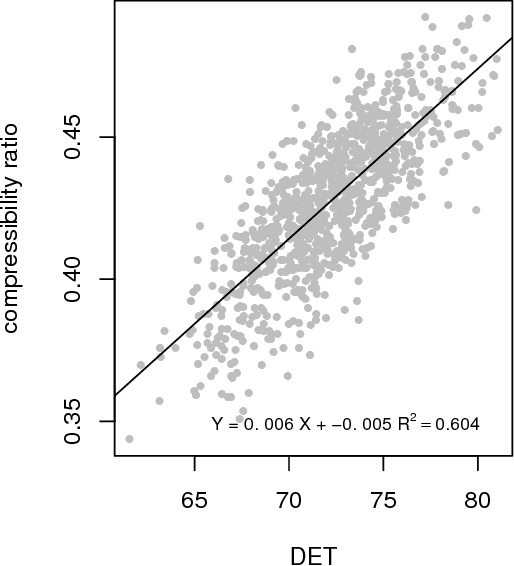
Writing and reading are dynamic processes. As an author composes a text, a sequence of words is produced. This sequence is one that, the author hopes, causes a revisitation of certain thoughts and ideas in others. These processes of composition and revisitation by readers are ordered in time. This means that text itself can be investigated under the lens of dynamical systems. A common technique for analyzing the behavior of dynamical systems, known as recurrence quantification analysis (RQA), can be used as a method for analyzing sequential structure of text. RQA treats text as a sequential measurement, much like a time series, and can thus be seen as a kind of dynamic natural language processing (NLP). The extension has several benefits. Because it is part of a suite of time series analysis tools, many measures can be extracted in one common framework. Secondly, the measures have a close relationship with some commonly used measures from natural language processing. Finally, using recurrence analysis offers an opportunity expand analysis of text by developing theoretical descriptions derived from complex dynamic systems. We showcase an example analysis on 8,000 texts from the Gutenberg Project, compare it to well-known NLP approaches, and describe an R package (crqanlp) that can be used in conjunction with R library crqa.
Cross-Recurrence Quantification Analysis of Categorical and Continuous Time Series: an R package
Oct 03, 2013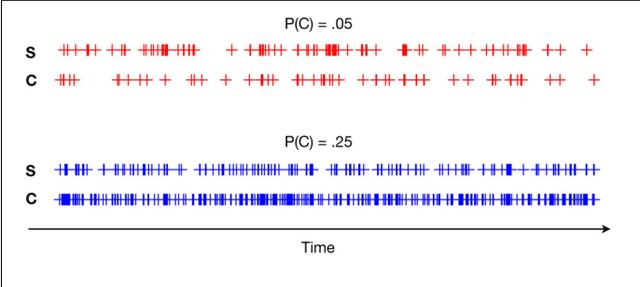

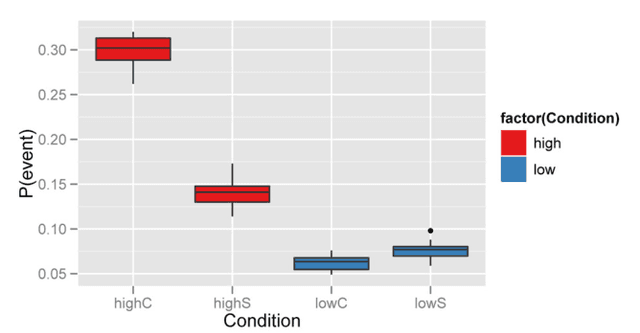
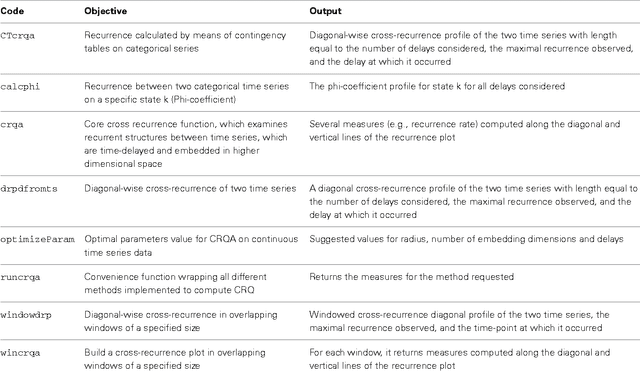
This paper describes the R package crqa to perform cross-recurrence quantification analysis of two time series of either a categorical or continuous nature. Streams of behavioral information, from eye movements to linguistic elements, unfold over time. When two people interact, such as in conversation, they often adapt to each other, leading these behavioral levels to exhibit recurrent states. In dialogue, for example, interlocutors adapt to each other by exchanging interactive cues: smiles, nods, gestures, choice of words, and so on. In order for us to capture closely the goings-on of dynamic interaction, and uncover the extent of coupling between two individuals, we need to quantify how much recurrence is taking place at these levels. Methods available in crqa would allow researchers in cognitive science to pose such questions as how much are two people recurrent at some level of analysis, what is the characteristic lag time for one person to maximally match another, or whether one person is leading another. First, we set the theoretical ground to understand the difference between 'correlation' and 'co-visitation' when comparing two time series, using an aggregative or cross-recurrence approach. Then, we describe more formally the principles of cross-recurrence, and show with the current package how to carry out analyses applying them. We end the paper by comparing computational efficiency, and results' consistency, of crqa R package, with the benchmark MATLAB toolbox crptoolbox. We show perfect comparability between the two libraries on both levels.
Random Sentences from a Generalized Phrase-Structure Grammar Interpreter
Feb 14, 2007In numerous domains in cognitive science it is often useful to have a source for randomly generated corpora. These corpora may serve as a foundation for artificial stimuli in a learning experiment (e.g., Ellefson & Christiansen, 2000), or as input into computational models (e.g., Christiansen & Dale, 2001). The following compact and general C program interprets a phrase-structure grammar specified in a text file. It follows parameters set at a Unix or Unix-based command-line and generates a corpus of random sentences from that grammar.