 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascaded encoders for fine-tuning ASR models on overlapped speech
Jun 28, 2023



Multi-talker speech recognition (MT-ASR) has been shown to improve ASR performance on speech containing overlapping utterances from more than one speaker. Multi-talker models have typically been trained from scratch using simulated or actual overlapping speech datasets. On the other hand, the trend in ASR has been to train foundation models using massive datasets collected from a wide variety of task domains. Given the scale of these models and their ability to generalize well across a variety of domains, it makes sense to consider scenarios where a foundation model is augmented with multi-talker capability. This paper presents an MT-ASR model formed by combining a well-trained foundation model with a multi-talker mask model in a cascaded RNN-T encoder configuration. Experimental results show that the cascade configuration provides improved WER on overlapping speech utterances with respect to a baseline multi-talker model without sacrificing performance achievable by the foundation model on non-overlapping utterances.
End-to-end multi-talker audio-visual ASR using an active speaker attention module
Apr 01, 2022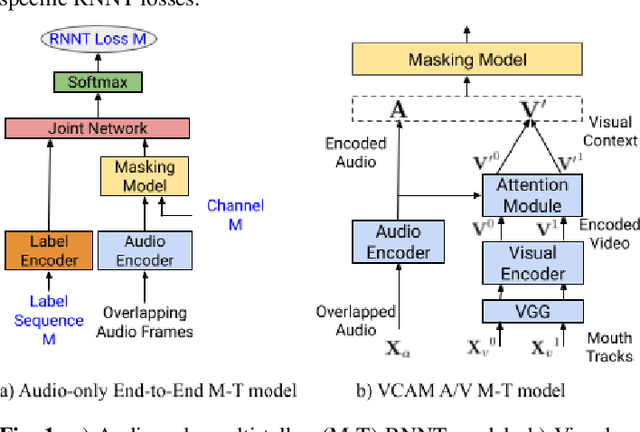
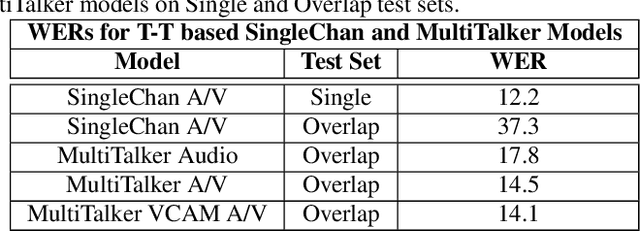
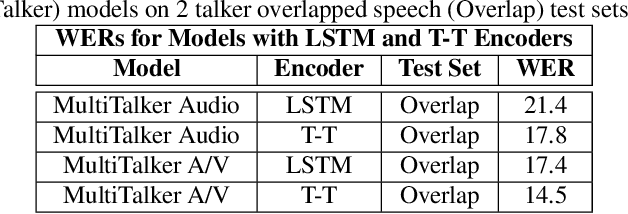
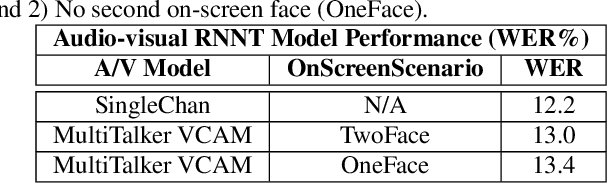
This paper presents a new approach for end-to-end audio-visual multi-talker speech recognition. The approach, referred to here as the visual context attention model (VCAM), is important because it uses the available video information to assign decoded text to one of multiple visible faces. This essentially resolves the label ambiguity issue associated with most multi-talker modeling approaches which can decode multiple label strings but cannot assign the label strings to the correct speakers. This is implemented as a transformer-transducer based end-to-end model and evaluated using a two speaker audio-visual overlapping speech dataset created from YouTube videos. It is shown in the paper that the VCAM model improves performance with respect to previously reported audio-only and audio-visual multi-talker ASR systems.