 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end multi-talker audio-visual ASR using an active speaker attention module
Paper and Code
Apr 01, 2022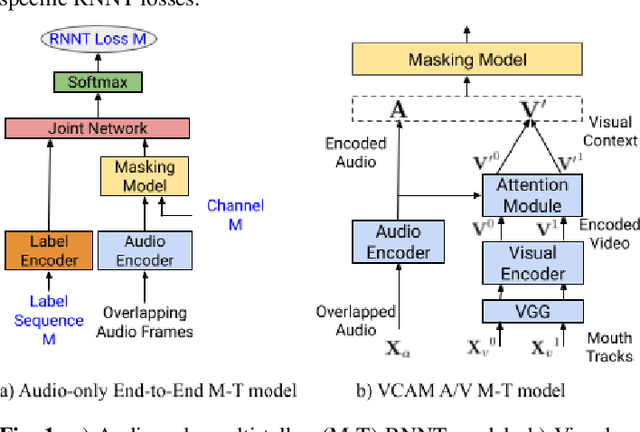
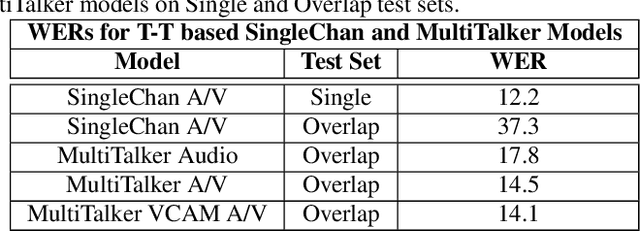
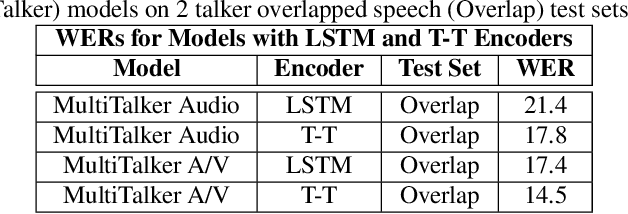
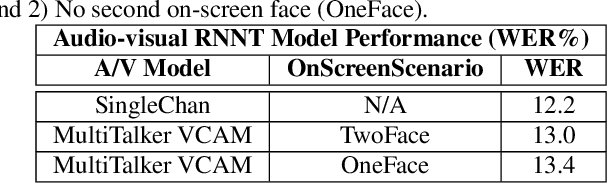
This paper presents a new approach for end-to-end audio-visual multi-talker speech recognition. The approach, referred to here as the visual context attention model (VCAM), is important because it uses the available video information to assign decoded text to one of multiple visible faces. This essentially resolves the label ambiguity issue associated with most multi-talker modeling approaches which can decode multiple label strings but cannot assign the label strings to the correct speakers. This is implemented as a transformer-transducer based end-to-end model and evaluated using a two speaker audio-visual overlapping speech dataset created from YouTube videos. It is shown in the paper that the VCAM model improves performance with respect to previously reported audio-only and audio-visual multi-talker ASR systems.