 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePuoBERTa: Training and evaluation of a curated language model for Setswana
Oct 24, 2023Natural language processing (NLP) has made significant progress for well-resourced languages such as English but lagged behind for low-resource languages like Setswana. This paper addresses this gap by presenting PuoBERTa, a customised masked language model trained specifically for Setswana. We cover how we collected, curated, and prepared diverse monolingual texts to generate a high-quality corpus for PuoBERTa's training. Building upon previous efforts in creating monolingual resources for Setswana, we evaluated PuoBERTa across several NLP tasks, including part-of-speech (POS) tagging, named entity recognition (NER), and news categorisation. Additionally, we introduced a new Setswana news categorisation dataset and provided the initial benchmarks using PuoBERTa. Our work demonstrates the efficacy of PuoBERTa in fostering NLP capabilities for understudied languages like Setswana and paves the way for future research directions.
Preparing the Vuk'uzenzele and ZA-gov-multilingual South African multilingual corpora
Mar 07, 2023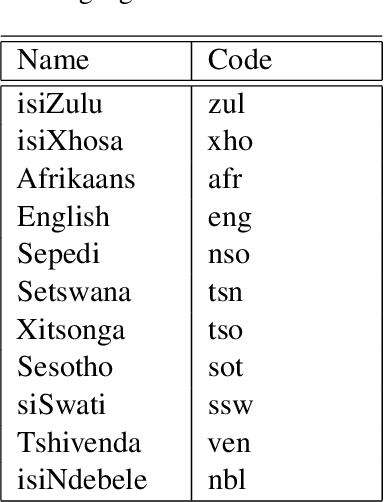
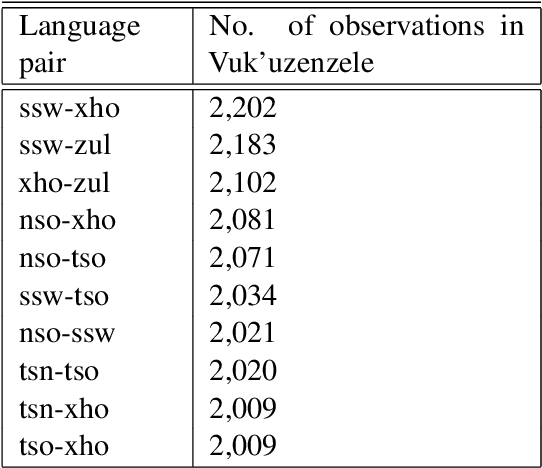
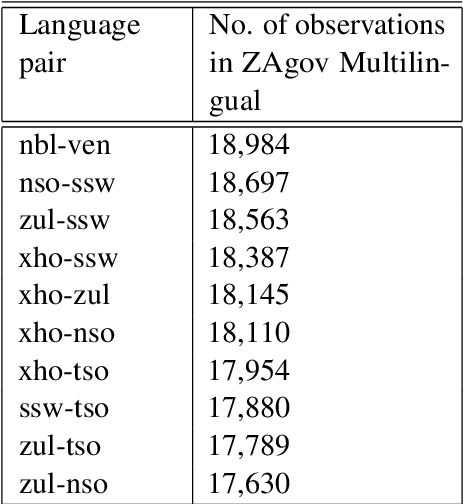
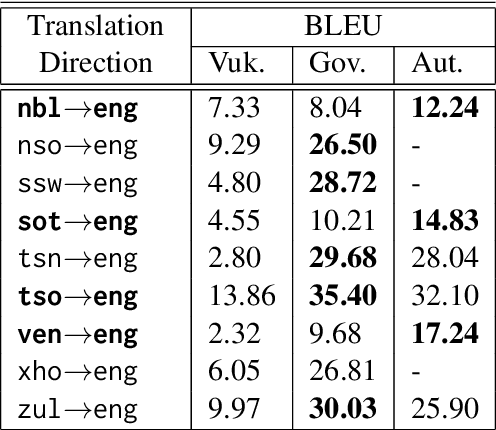
This paper introduces two multilingual government themed corpora in various South African languages. The corpora were collected by gathering the South African Government newspaper (Vuk'uzenzele), as well as South African government speeches (ZA-gov-multilingual), that are translated into all 11 South African official languages. The corpora can be used for a myriad of downstream NLP tasks. The corpora were created to allow researchers to study the language used in South African government publications, with a focus on understanding how South African government officials communicate with their constituents. In this paper we highlight the process of gathering, cleaning and making available the corpora. We create parallel sentence corpora for Neural Machine Translation (NMT) tasks using Language-Agnostic Sentence Representations (LASER) embeddings. With these aligned sentences we then provide NMT benchmarks for 9 indigenous languages by fine-tuning a massively multilingual pre-trained language model. \end{abstra