 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Hype: Embeddings vs. Prompting for Multiclass Classification Tasks
Apr 09, 2025Are traditional classification approaches irrelevant in this era of AI hype? We show that there are multiclass classification problems where predictive models holistically outperform LLM prompt-based frameworks. Given text and images from home-service project descriptions provided by Thumbtack customers, we build embeddings-based softmax models that predict the professional category (e.g., handyman, bathroom remodeling) associated with each problem description. We then compare against prompts that ask state-of-the-art LLM models to solve the same problem. We find that the embeddings approach outperforms the best LLM prompts in terms of accuracy, calibration, latency, and financial cost. In particular, the embeddings approach has 49.5% higher accuracy than the prompting approach, and its superiority is consistent across text-only, image-only, and text-image problem descriptions. Furthermore, it yields well-calibrated probabilities, which we later use as confidence signals to provide contextualized user experience during deployment. On the contrary, prompting scores are overly uninformative. Finally, the embeddings approach is 14 and 81 times faster than prompting in processing images and text respectively, while under realistic deployment assumptions, it can be up to 10 times cheaper. Based on these results, we deployed a variation of the embeddings approach, and through A/B testing we observed performance consistent with our offline analysis. Our study shows that for multiclass classification problems that can leverage proprietary datasets, an embeddings-based approach may yield unequivocally better results. Hence, scientists, practitioners, engineers, and business leaders can use our study to go beyond the hype and consider appropriate predictive models for their classification use cases.
Position bias in features
Feb 04, 2024The purpose of modeling document relevance for search engines is to rank better in subsequent searches. Document-specific historical click-through rates can be important features in a dynamic ranking system which updates as we accumulate more sample. This paper describes the properties of several such features, and tests them in controlled experiments. Extending the inverse propensity weighting method to documents creates an unbiased estimate of document relevance. This feature can approximate relevance accurately, leading to near-optimal ranking in ideal circumstances. However, it has high variance that is increasing with respect to the degree of position bias. Furthermore, inaccurate position bias estimation leads to poor performance. Under several scenarios this feature can perform worse than biased click-through rates. This paper underscores the need for accurate position bias estimation, and is unique in suggesting simultaneous use of biased and unbiased position bias features.
Measurement and applications of position bias in a marketplace search engine
Jun 23, 2022
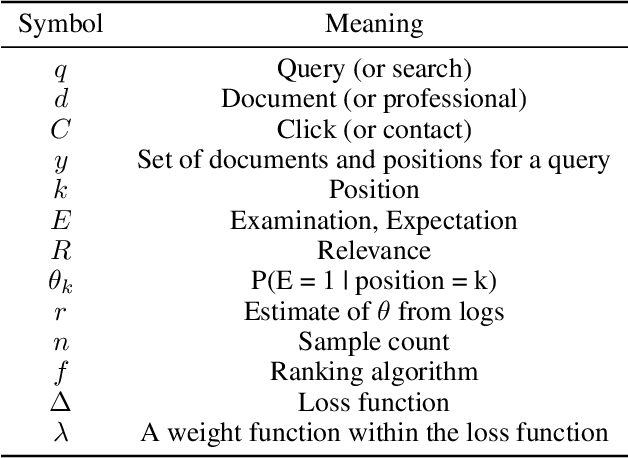


Search engines intentionally influence user behavior by picking and ranking the list of results. Users engage with the highest results both because of their prominent placement and because they are typically the most relevant documents. Search engine ranking algorithms need to identify relevance while incorporating the influence of the search engine itself. This paper describes our efforts at Thumbtack to understand the impact of ranking, including the empirical results of a randomization program. In the context of a consumer marketplace we discuss practical details of model choice, experiment design, bias calculation, and machine learning model adaptation. We include a novel discussion of how ranking bias may not only affect labels, but also model features. The randomization program led to improved models, motivated internal scenario analysis, and enabled user-facing scenario tooling.