 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Confidants: How do People Experience Trust in Emotional Support from Generative AI?
Jan 23, 2026People are increasingly turning to generative AI (e.g., ChatGPT, Gemini, Copilot) for emotional support and companionship. While trust is likely to play a central role in enabling these informal and unsupervised interactions, we still lack an understanding of how people develop and experience it in this context. Seeking to fill this gap, we recruited 24 frequent users of generative AI for emotional support and conducted a qualitative study consisting of diary entries about interactions, transcripts of chats with AI, and in-depth interviews. Our results suggest important novel drivers of trust in this context: familiarity emerging from personalisation, nuanced mental models of generative AI, and awareness of people's control over conversations. Notably, generative AI's homogeneous use of personalised, positive, and persuasive language appears to promote some of these trust-building factors. However, this also seems to discourage other trust-related behaviours, such as remembering that generative AI is a machine trained to converse in human language. We present implications for future research that are likely to become critical as the use of generative AI for emotional support increasingly overlaps with therapeutic work.
Visualizing Neural Network Imagination
May 10, 2024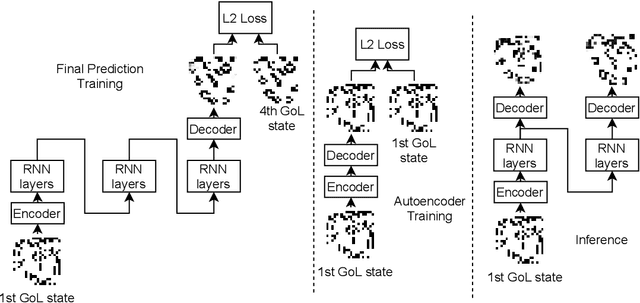
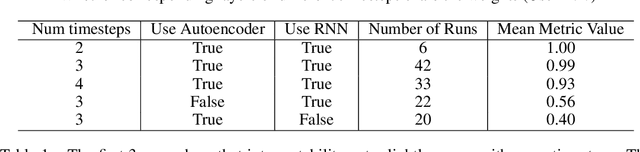


In certain situations, neural networks will represent environment states in their hidden activations. Our goal is to visualize what environment states the networks are representing. We experiment with a recurrent neural network (RNN) architecture with a decoder network at the end. After training, we apply the decoder to the intermediate representations of the network to visualize what they represent. We define a quantitative interpretability metric and use it to demonstrate that hidden states can be highly interpretable on a simple task. We also develop autoencoder and adversarial techniques and show that benefit interpretability.
Active learning to optimise time-expensive algorithm selection
Sep 07, 2019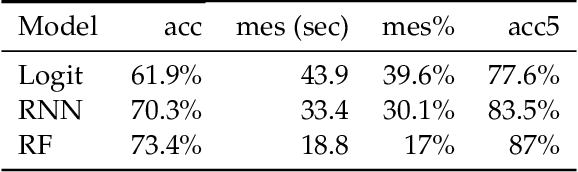
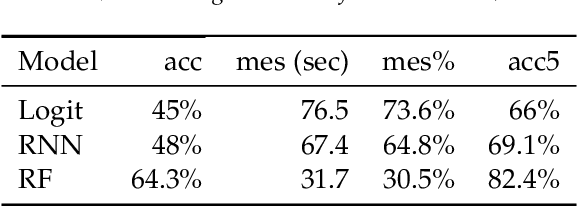
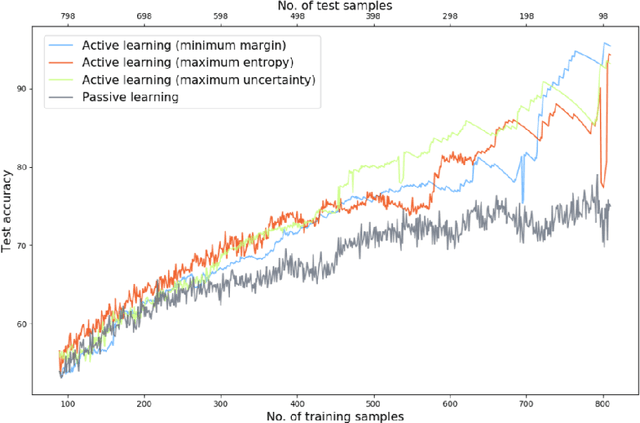
Hard optimisation problems such as Boolean Satisfiability typically have long solving times and can usually be solved by many algorithms, although the performance can vary widely in practice. Research has shown that no single algorithm outperforms all the others; thus, it is crucial to select the best algorithm for a given problem. Supervised machine learning models can accurately predict which solver is best for a given problem, but they require first to run every solver in the portfolio for all examples available to create labelled data. As this approach cannot scale, we developed an active learning framework that addresses this problem by constructing an optimal training set, so that the learner can achieve higher or equal performances with less training data. Our work proves that active learning is beneficial for algorithm selection techniques and provides practical guidance to incorporate into existing systems.