 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-R2: Fair Credit Assignment for Long-Horizon Memory-Augmented LLM Agents
May 20, 2026Memory-augmented LLM agents enable interactions that extend beyond finite context windows by storing, updating, and reusing information across sessions. However, training such agents with reinforcement learning in multi-session environments is challenging because memory turns the agent's past actions into part of its future environment. Once different rollouts write, update, or delete different memories, they no longer share the same intermediate memory state, making trajectory-level comparisons fundamentally unfair. This violates a key assumption behind group-relative methods such as GRPO, where rollouts are compared as if they were sampled from the same effective environment. Consequently, trajectory-level rewards provide noisy or biased credit signals for long-horizon memory operations. To address this challenge, we introduce Memory-R2, a training framework for long-horizon memory-augmented LLM agents. Its core algorithm, LoGo-GRPO, combines local and global group-relative optimization. The global objective preserves end-to-end learning from long-horizon trajectory-level rewards, while local rerollouts compare different memory-operation outcomes from the same intermediate memory state, yielding fairer group comparisons and more precise supervision for memory construction. Beyond credit assignment, Memory-R2 jointly optimizes memory formation and memory evolution with a shared-parameter co-learning design, where a fact extractor and a memory manager are instantiated from the same LLM backbone through role-specific prompts. To stabilize multi-step RL over long memory horizons, we adopt a progressive curriculum that increases the training horizon from 8 to 16 to 32 sessions. Together, these components provide an effective training paradigm for memory-augmented LLM agents in long-horizon multi-session settings.
Q-Learning for Conflict Resolution in B5G Network Automation
Jul 28, 2021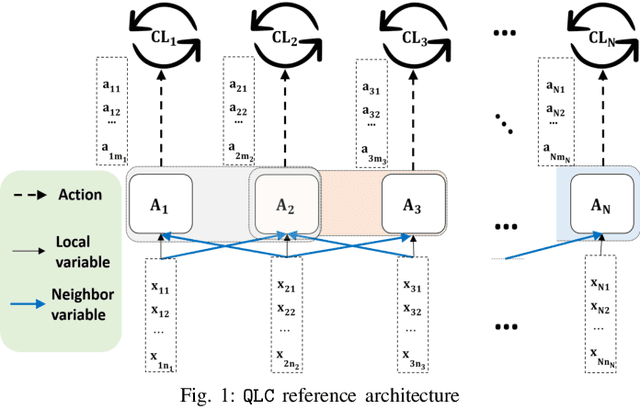
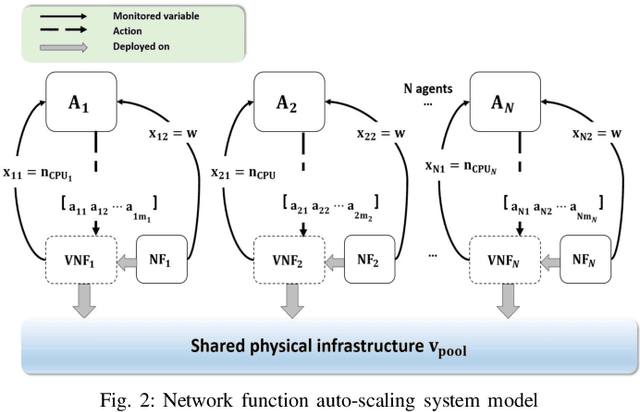
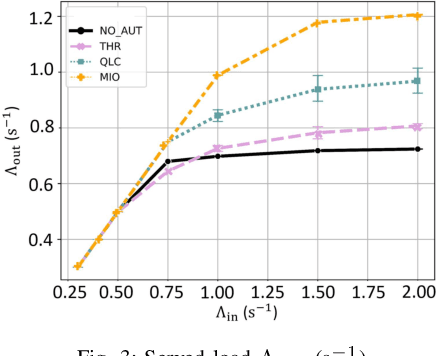
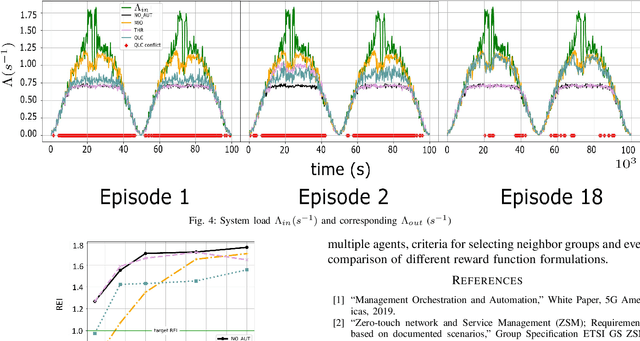
Network automation is gaining significant attention in the development of B5G networks, primarily for reducing operational complexity, expenditures and improving network efficiency. Concurrently operating closed loops aiming for individual optimization targets may cause conflicts which, left unresolved, would lead to significant degradation in network Key Performance Indicators (KPIs), thereby resulting in sub-optimal network performance. Centralized coordination, albeit optimal, is impractical in large scale networks and for time-critical applications. Decentralized approaches are therefore envisaged in the evolution to B5G and subsequently, 6G networks. This work explores pervasive intelligence for conflict resolution in network automation, as an alternative to centralized orchestration. A Q-Learning decentralized approach to network automation is proposed, and an application to network slice auto-scaling is designed and evaluated. Preliminary results highlight the potential of the proposed scheme and justify further research work in this direction.