 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinary domain generalization for sparsifying binary neural networks
Jun 23, 2023Binary neural networks (BNNs) are an attractive solution for developing and deploying deep neural network (DNN)-based applications in resource constrained devices. Despite their success, BNNs still suffer from a fixed and limited compression factor that may be explained by the fact that existing pruning methods for full-precision DNNs cannot be directly applied to BNNs. In fact, weight pruning of BNNs leads to performance degradation, which suggests that the standard binarization domain of BNNs is not well adapted for the task. This work proposes a novel more general binary domain that extends the standard binary one that is more robust to pruning techniques, thus guaranteeing improved compression and avoiding severe performance losses. We demonstrate a closed-form solution for quantizing the weights of a full-precision network into the proposed binary domain. Finally, we show the flexibility of our method, which can be combined with other pruning strategies. Experiments over CIFAR-10 and CIFAR-100 demonstrate that the novel approach is able to generate efficient sparse networks with reduced memory usage and run-time latency, while maintaining performance.
Sparsifying Binary Networks
Jul 11, 2022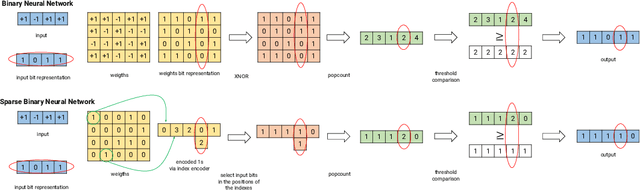
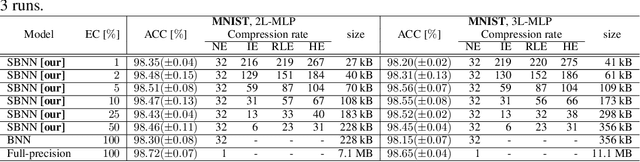
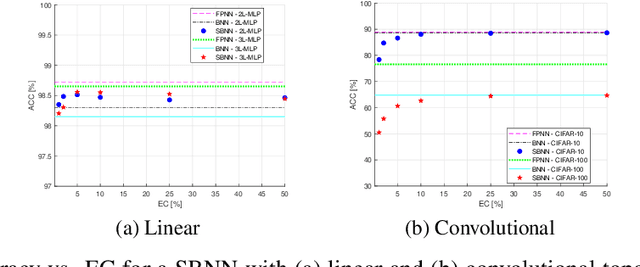

Binary neural networks (BNNs) have demonstrated their ability to solve complex tasks with comparable accuracy as full-precision deep neural networks (DNNs), while also reducing computational power and storage requirements and increasing the processing speed. These properties make them an attractive alternative for the development and deployment of DNN-based applications in Internet-of-Things (IoT) devices. Despite the recent improvements, they suffer from a fixed and limited compression factor that may result insufficient for certain devices with very limited resources. In this work, we propose sparse binary neural networks (SBNNs), a novel model and training scheme which introduces sparsity in BNNs and a new quantization function for binarizing the network's weights. The proposed SBNN is able to achieve high compression factors and it reduces the number of operations and parameters at inference time. We also provide tools to assist the SBNN design, while respecting hardware resource constraints. We study the generalization properties of our method for different compression factors through a set of experiments on linear and convolutional networks on three datasets. Our experiments confirm that SBNNs can achieve high compression rates, without compromising generalization, while further reducing the operations of BNNs, making SBNNs a viable option for deploying DNNs in cheap, low-cost, limited-resources IoT devices and sensors.