 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Match Made in Heaven? Matching Test Cases and Vulnerabilities With the VUTECO Approach
Feb 05, 2025



Software vulnerabilities are commonly detected via static analysis, penetration testing, and fuzzing. They can also be found by running unit tests - so-called vulnerability-witnessing tests - that stimulate the security-sensitive behavior with crafted inputs. Developing such tests is difficult and time-consuming; thus, automated data-driven approaches could help developers intercept vulnerabilities earlier. However, training and validating such approaches require a lot of data, which is currently scarce. This paper introduces VUTECO, a deep learning-based approach for collecting instances of vulnerability-witnessing tests from Java repositories. VUTECO carries out two tasks: (1) the "Finding" task to determine whether a test case is security-related, and (2) the "Matching" task to relate a test case to the exact vulnerability it is witnessing. VUTECO successfully addresses the Finding task, achieving perfect precision and 0.83 F0.5 score on validated test cases in VUL4J and returning 102 out of 145 (70%) correct security-related test cases from 244 open-source Java projects. Despite showing sufficiently good performance for the Matching task - i.e., 0.86 precision and 0.68 F0.5 score - VUTECO failed to retrieve any valid match in the wild. Nevertheless, we observed that in almost all of the matches, the test case was still security-related despite being matched to the wrong vulnerability. In the end, VUTECO can help find vulnerability-witnessing tests, though the matching with the right vulnerability is yet to be solved; the findings obtained lay the stepping stone for future research on the matter.
Prompting Techniques for Secure Code Generation: A Systematic Investigation
Jul 09, 2024



Large Language Models (LLMs) are gaining momentum in software development with prompt-driven programming enabling developers to create code from natural language (NL) instructions. However, studies have questioned their ability to produce secure code and, thereby, the quality of prompt-generated software. Alongside, various prompting techniques that carefully tailor prompts have emerged to elicit optimal responses from LLMs. Still, the interplay between such prompting strategies and secure code generation remains under-explored and calls for further investigations. OBJECTIVE: In this study, we investigate the impact of different prompting techniques on the security of code generated from NL instructions by LLMs. METHOD: First we perform a systematic literature review to identify the existing prompting techniques that can be used for code generation tasks. A subset of these techniques are evaluated on GPT-3, GPT-3.5, and GPT-4 models for secure code generation. For this, we used an existing dataset consisting of 150 NL security-relevant code-generation prompts. RESULTS: Our work (i) classifies potential prompting techniques for code generation (ii) adapts and evaluates a subset of the identified techniques for secure code generation tasks and (iii) observes a reduction in security weaknesses across the tested LLMs, especially after using an existing technique called Recursive Criticism and Improvement (RCI), contributing valuable insights to the ongoing discourse on LLM-generated code security.
LLMSecEval: A Dataset of Natural Language Prompts for Security Evaluations
Mar 16, 2023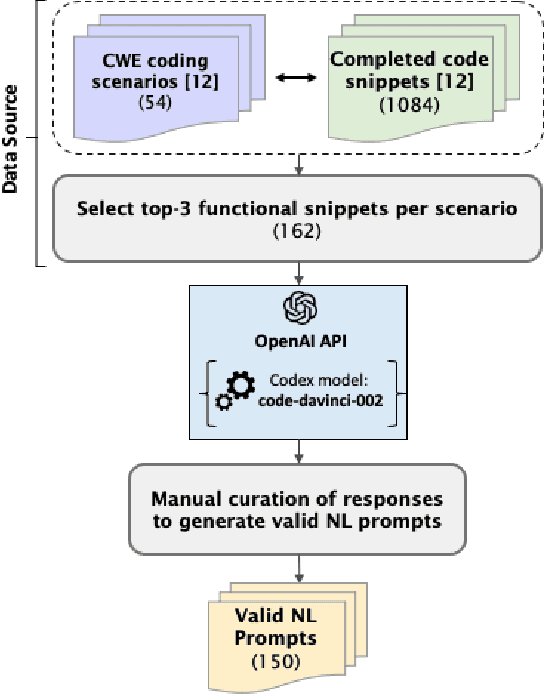

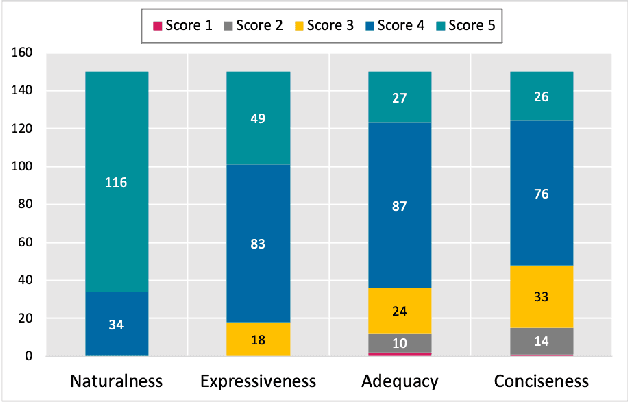
Large Language Models (LLMs) like Codex are powerful tools for performing code completion and code generation tasks as they are trained on billions of lines of code from publicly available sources. Moreover, these models are capable of generating code snippets from Natural Language (NL) descriptions by learning languages and programming practices from public GitHub repositories. Although LLMs promise an effortless NL-driven deployment of software applications, the security of the code they generate has not been extensively investigated nor documented. In this work, we present LLMSecEval, a dataset containing 150 NL prompts that can be leveraged for assessing the security performance of such models. Such prompts are NL descriptions of code snippets prone to various security vulnerabilities listed in MITRE's Top 25 Common Weakness Enumeration (CWE) ranking. Each prompt in our dataset comes with a secure implementation example to facilitate comparative evaluations against code produced by LLMs. As a practical application, we show how LLMSecEval can be used for evaluating the security of snippets automatically generated from NL descriptions.
GitHub Considered Harmful? Analyzing Open-Source Projects for the Automatic Generation of Cryptographic API Call Sequences
Nov 24, 2022GitHub is a popular data repository for code examples. It is being continuously used to train several AI-based tools to automatically generate code. However, the effectiveness of such tools in correctly demonstrating the usage of cryptographic APIs has not been thoroughly assessed. In this paper, we investigate the extent and severity of misuses, specifically caused by incorrect cryptographic API call sequences in GitHub. We also analyze the suitability of GitHub data to train a learning-based model to generate correct cryptographic API call sequences. For this, we manually extracted and analyzed the call sequences from GitHub. Using this data, we augmented an existing learning-based model called DeepAPI to create two security-specific models that generate cryptographic API call sequences for a given natural language (NL) description. Our results indicate that it is imperative to not neglect the misuses in API call sequences while using data sources like GitHub, to train models that generate code.