 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting Techniques for Secure Code Generation: A Systematic Investigation
Jul 09, 2024



Large Language Models (LLMs) are gaining momentum in software development with prompt-driven programming enabling developers to create code from natural language (NL) instructions. However, studies have questioned their ability to produce secure code and, thereby, the quality of prompt-generated software. Alongside, various prompting techniques that carefully tailor prompts have emerged to elicit optimal responses from LLMs. Still, the interplay between such prompting strategies and secure code generation remains under-explored and calls for further investigations. OBJECTIVE: In this study, we investigate the impact of different prompting techniques on the security of code generated from NL instructions by LLMs. METHOD: First we perform a systematic literature review to identify the existing prompting techniques that can be used for code generation tasks. A subset of these techniques are evaluated on GPT-3, GPT-3.5, and GPT-4 models for secure code generation. For this, we used an existing dataset consisting of 150 NL security-relevant code-generation prompts. RESULTS: Our work (i) classifies potential prompting techniques for code generation (ii) adapts and evaluates a subset of the identified techniques for secure code generation tasks and (iii) observes a reduction in security weaknesses across the tested LLMs, especially after using an existing technique called Recursive Criticism and Improvement (RCI), contributing valuable insights to the ongoing discourse on LLM-generated code security.
LLMSecEval: A Dataset of Natural Language Prompts for Security Evaluations
Mar 16, 2023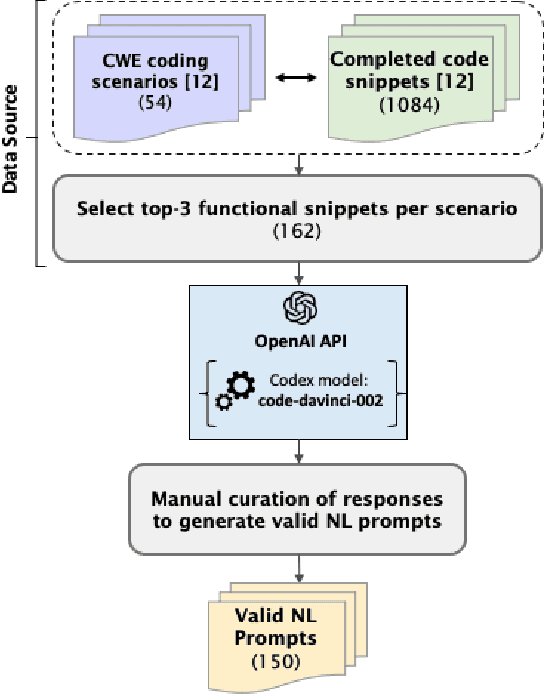

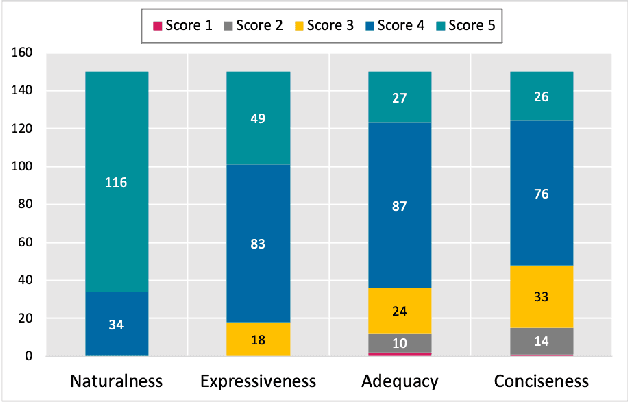
Large Language Models (LLMs) like Codex are powerful tools for performing code completion and code generation tasks as they are trained on billions of lines of code from publicly available sources. Moreover, these models are capable of generating code snippets from Natural Language (NL) descriptions by learning languages and programming practices from public GitHub repositories. Although LLMs promise an effortless NL-driven deployment of software applications, the security of the code they generate has not been extensively investigated nor documented. In this work, we present LLMSecEval, a dataset containing 150 NL prompts that can be leveraged for assessing the security performance of such models. Such prompts are NL descriptions of code snippets prone to various security vulnerabilities listed in MITRE's Top 25 Common Weakness Enumeration (CWE) ranking. Each prompt in our dataset comes with a secure implementation example to facilitate comparative evaluations against code produced by LLMs. As a practical application, we show how LLMSecEval can be used for evaluating the security of snippets automatically generated from NL descriptions.
GitHub Considered Harmful? Analyzing Open-Source Projects for the Automatic Generation of Cryptographic API Call Sequences
Nov 24, 2022GitHub is a popular data repository for code examples. It is being continuously used to train several AI-based tools to automatically generate code. However, the effectiveness of such tools in correctly demonstrating the usage of cryptographic APIs has not been thoroughly assessed. In this paper, we investigate the extent and severity of misuses, specifically caused by incorrect cryptographic API call sequences in GitHub. We also analyze the suitability of GitHub data to train a learning-based model to generate correct cryptographic API call sequences. For this, we manually extracted and analyzed the call sequences from GitHub. Using this data, we augmented an existing learning-based model called DeepAPI to create two security-specific models that generate cryptographic API call sequences for a given natural language (NL) description. Our results indicate that it is imperative to not neglect the misuses in API call sequences while using data sources like GitHub, to train models that generate code.
Should I Get Involved? On the Privacy Perils of Mining Software Repositories for Research Participants
Feb 24, 2022Mining Software Repositories (MSRs) is an evidence-based methodology that cross-links data to uncover actionable information about software systems. Empirical studies in software engineering often leverage MSR techniques as they allow researchers to unveil issues and flaws in software development so as to analyse the different factors contributing to them. Hence, counting on fine-grained information about the repositories and sources being mined (e.g., server names, and contributors' identities) is essential for the reproducibility and transparency of MSR studies. However, this can also introduce threats to participants' privacy as their identities may be linked to flawed/sub-optimal programming practices (e.g., code smells, improper documentation), or vice-versa. Moreover, this can be extensible to close collaborators and community members resulting "guilty by association". This position paper aims to start a discussion about indirect participation in MSRs investigations, the dichotomy of 'privacy vs. utility' regarding sharing non-aggregated data, and its effects on privacy restrictions and ethical considerations for participant involvement.