 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMERGE -- A Bimodal Dataset for Static Music Emotion Recognition
Jul 08, 2024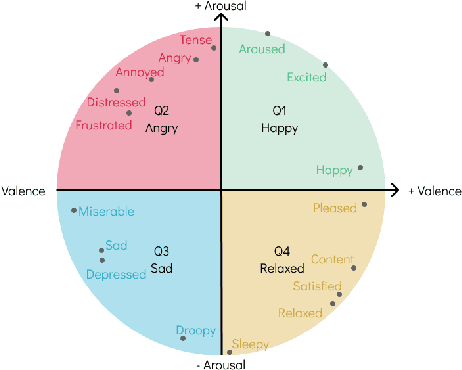
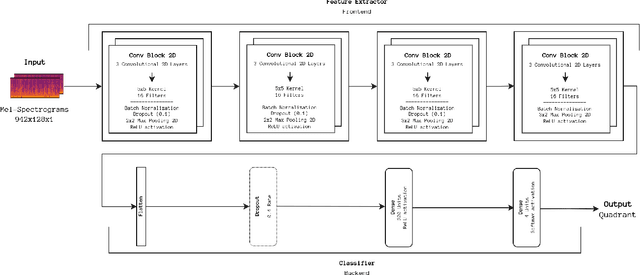
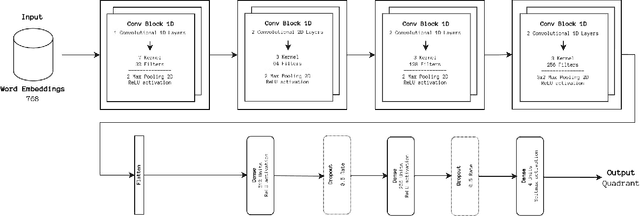
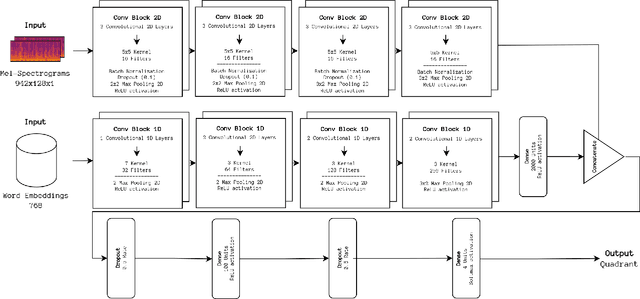
The Music Emotion Recognition (MER) field has seen steady developments in recent years, with contributions from feature engineering, machine learning, and deep learning. The landscape has also shifted from audio-centric systems to bimodal ensembles that combine audio and lyrics. However, a severe lack of public and sizeable bimodal databases has hampered the development and improvement of bimodal audio-lyrics systems. This article proposes three new audio, lyrics, and bimodal MER research datasets, collectively called MERGE, created using a semi-automatic approach. To comprehensively assess the proposed datasets and establish a baseline for benchmarking, we conducted several experiments for each modality, using feature engineering, machine learning, and deep learning methodologies. In addition, we propose and validate fixed train-validate-test splits. The obtained results confirm the viability of the proposed datasets, achieving the best overall result of 79.21% F1-score for bimodal classification using a deep neural network.