 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA state of the art of urban reconstruction: street, street network, vegetation, urban feature
Jan 18, 2018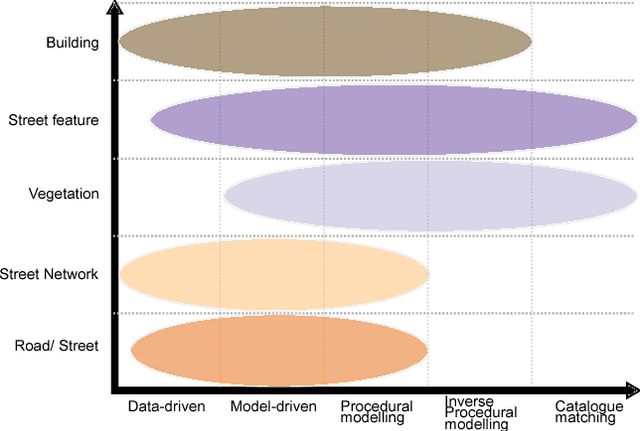


World population is raising, especially the part of people living in cities. With increased population and complex roles regarding their inhabitants and their surroundings, cities concentrate difficulties for design, planning and analysis. These tasks require a way to reconstruct/model a city. Traditionally, much attention has been given to buildings reconstruction, yet an essential part of city were neglected: streets. Streets reconstruction has been seldom researched. Streets are also complex compositions of urban features, and have a unique role for transportation (as they comprise roads). We aim at completing the recent state of the art for building reconstruction (Musialski2012) by considering all other aspect of urban reconstruction. We introduce the need for city models. Because reconstruction always necessitates data, we first analyse which data are available. We then expose a state of the art of street reconstruction, street network reconstruction, urban features reconstruction/modelling, vegetation , and urban objects reconstruction/modelling. Although reconstruction strategies vary widely, we can order them by the role the model plays, from data driven approach, to model-based approach, to inverse procedural modelling and model catalogue matching. The main challenges seems to come from the complex nature of urban environment and from the limitations of the available data. Urban features have strong relationships, between them, and to their surrounding, as well as in hierarchical relations. Procedural modelling has the power to express these relations, and could be applied to the reconstruction of urban features via the Inverse Procedural Modelling paradigm.
Interactive in-base street model edit: how common GIS software and a database can serve as a custom Graphical User Interface
Jan 17, 2018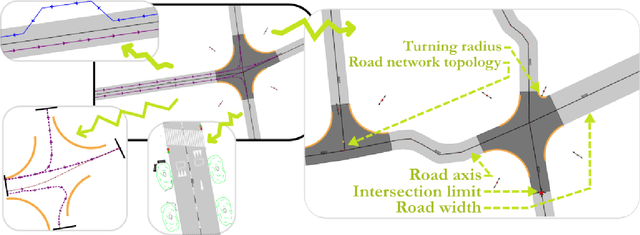
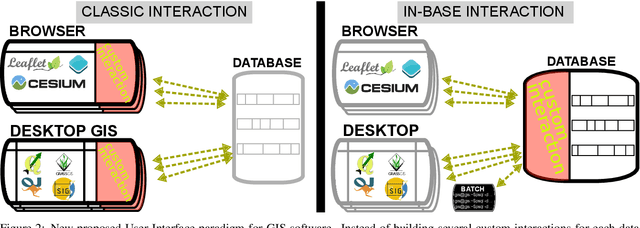
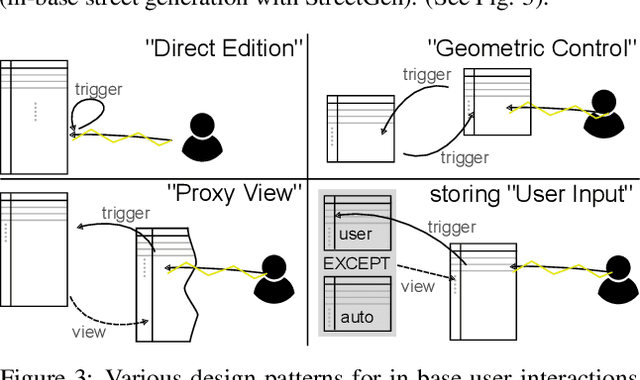
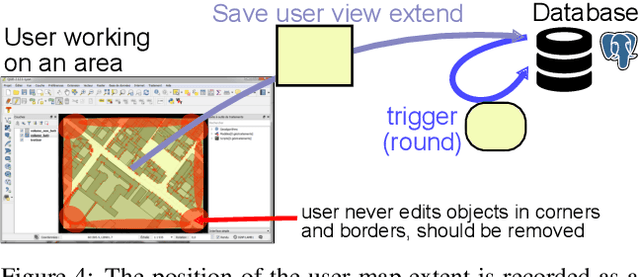
Our modern world produces an increasing quantity of data, and especially geospatial data, with advance of sensing technologies, and growing complexity and organisation of vector data. Tools are needed to efficiently create and edit those vector geospatial data. Procedural generation has been a tool of choice to generate strongly organised data, yet it may be hard to control. Because those data may be involved to take consequence-full real life decisions, user interactions are required to check data and edit it. The classical process to do so would be to build an adhoc Graphical User Interface (GUI) tool adapted for the model and method being used. This task is difficult, takes a large amount of resources, and is very specific to one model, making it hard to share and re-use. Besides, many common generic GUI already exists to edit vector data, each having its specialities. We propose a change of paradigm; instead of building a specific tool for one task, we use common GIS software as GUIs, and deport the specific interactions from the software to within the database. In this paradigm, GIS software simply modify geometry and attributes of database layers, and those changes are used by the database to perform automated task. This new paradigm has many advantages. The first one is genericity. With in-base interaction, any GIS software can be used to perform edition, whatever the software is a Desktop sofware or a web application. The second is concurrency and coherency. Because interaction is in-base, use of database features allows seamless multi-user work, and can guarantee that the data is in a coherent state. Last we propose tools to facilitate multi-user edits, both during the edit phase (each user knows what areas are edited by other users), and before and after edit (planning of edit, analyse of edited areas).
An octree cells occupancy geometric dimensionality descriptor for massive on-server point cloud visualisation and classification
Jan 15, 2018
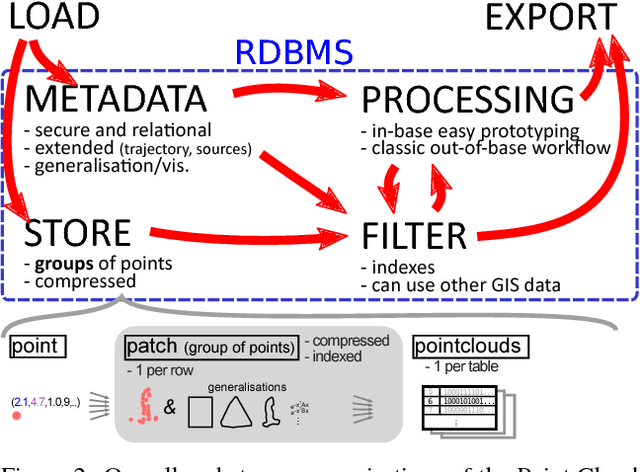
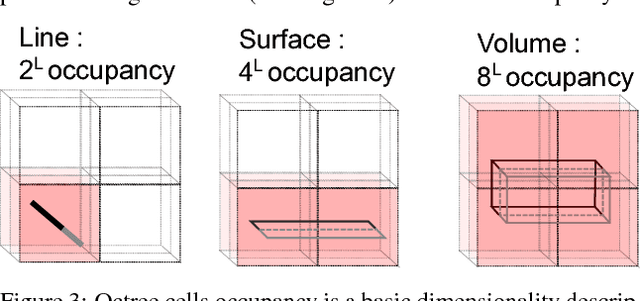
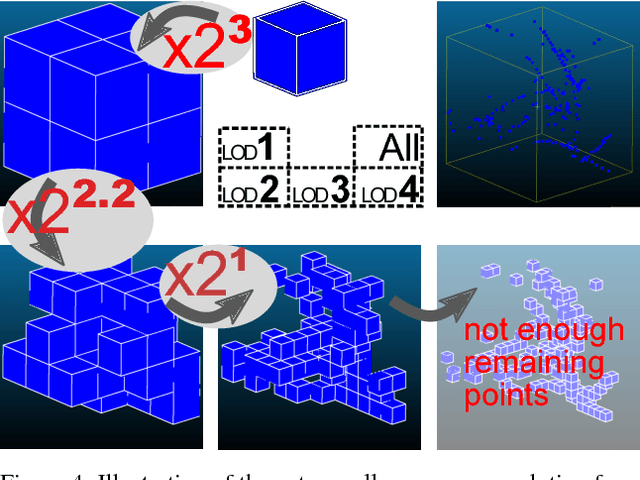
Lidar datasets are becoming more and more common. They are appreciated for their precise 3D nature, and have a wide range of applications, such as surface reconstruction, object detection, visualisation, etc. For all this applications, having additional semantic information per point has potential of increasing the quality and the efficiency of the application. In the last decade the use of Machine Learning and more specifically classification methods have proved to be successful to create this semantic information. In this paradigm, the goal is to classify points into a set of given classes (for instance tree, building, ground, other). Some of these methods use descriptors (also called feature) of a point to learn and predict its class. Designing the descriptors is then the heart of these methods. Descriptors can be based on points geometry and attributes, use contextual information, etc. Furthermore, descriptors can be used by humans for easier visual understanding and sometimes filtering. In this work we propose a new simple geometric descriptor that gives information about the implicit local dimensionality of the point cloud at various scale. For instance a tree seen from afar is more volumetric in nature (3D), yet locally each leaves is rather planar (2D). To do so we build an octree centred on the point to consider, and compare the variation of the occupancy of the cells across the levels of the octree. We compare this descriptor with the state of the art dimensionality descriptor and show its interest. We further test the descriptor for classification within the Point Cloud Server, and demonstrate efficiency and correctness results.