 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Nudging: Solving Average-Reward Semi-Markov Decision Processes as a Minimal Sequence of Cumulative Tasks
Apr 20, 2015
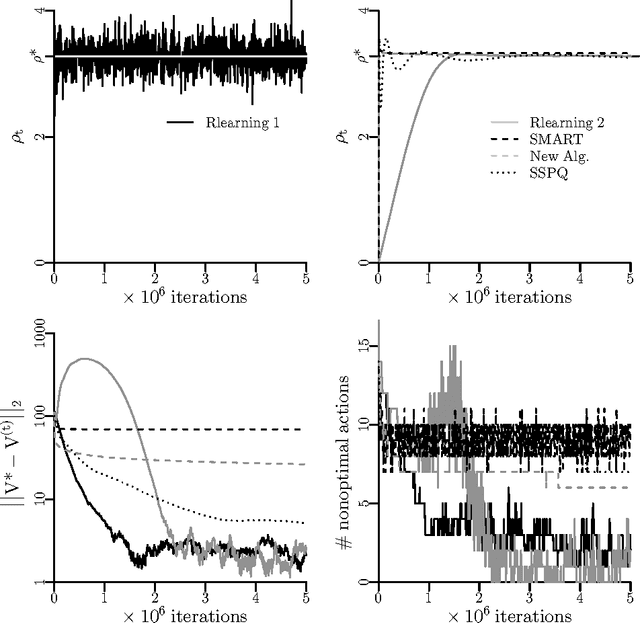

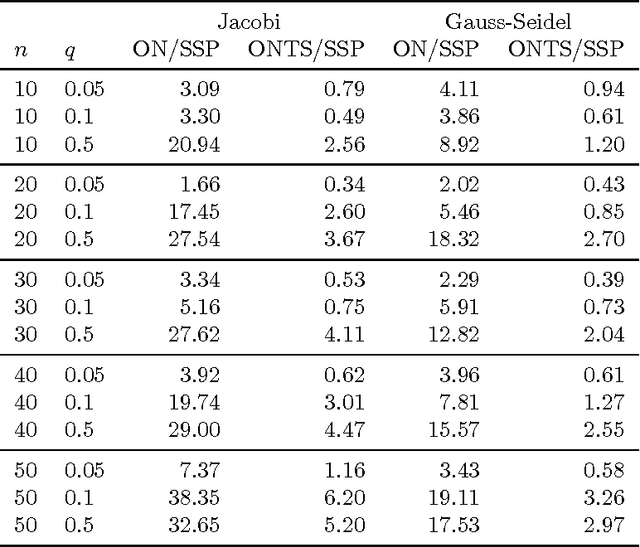
This paper describes a novel method to solve average-reward semi-Markov decision processes, by reducing them to a minimal sequence of cumulative reward problems. The usual solution methods for this type of problems update the gain (optimal average reward) immediately after observing the result of taking an action. The alternative introduced, optimal nudging, relies instead on setting the gain to some fixed value, which transitorily makes the problem a cumulative-reward task, solving it by any standard reinforcement learning method, and only then updating the gain in a way that minimizes uncertainty in a minmax sense. The rule for optimal gain update is derived by exploiting the geometric features of the w-l space, a simple mapping of the space of policies. The total number of cumulative reward tasks that need to be solved is shown to be small. Some experiments are presented to explore the features of the algorithm and to compare its performance with other approaches.