 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeServerless Federated Learning with flwr-serverless
Oct 23, 2023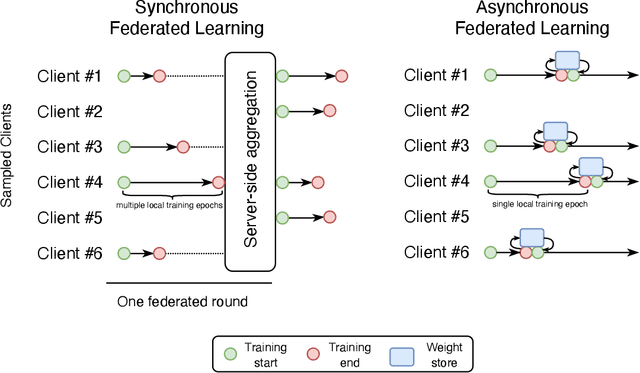
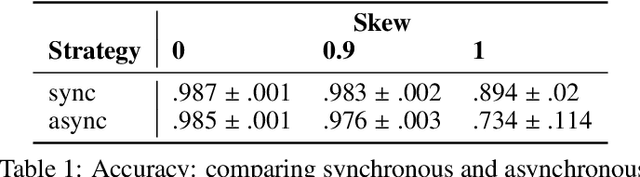
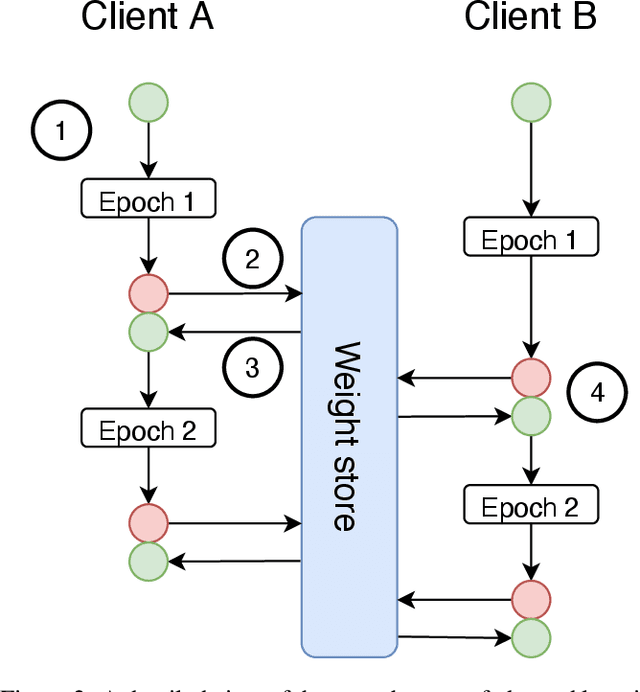
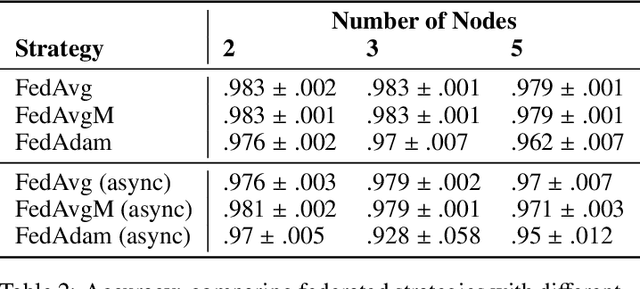
Federated learning is becoming increasingly relevant and popular as we witness a surge in data collection and storage of personally identifiable information. Alongside these developments there have been many proposals from governments around the world to provide more protections for individuals' data and a heightened interest in data privacy measures. As deep learning continues to become more relevant in new and existing domains, it is vital to develop strategies like federated learning that can effectively train data from different sources, such as edge devices, without compromising security and privacy. Recently, the Flower (\texttt{Flwr}) Python package was introduced to provide a scalable, flexible, and easy-to-use framework for implementing federated learning. However, to date, Flower is only able to run synchronous federated learning which can be costly and time-consuming to run because the process is bottlenecked by client-side training jobs that are slow or fragile. Here, we introduce \texttt{flwr-serverless}, a wrapper around the Flower package that extends its functionality to allow for both synchronous and asynchronous federated learning with minimal modification to Flower's design paradigm. Furthermore, our approach to federated learning allows the process to run without a central server, which increases the domains of application and accessibility of its use. This paper presents the design details and usage of this approach through a series of experiments that were conducted using public datasets. Overall, we believe that our approach decreases the time and cost to run federated training and provides an easier way to implement and experiment with federated learning systems.