 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Opponent Policy Detection in Multi-Agent MDPs: Real-Time Strategy Switch Identification Using Running Error Estimation
Jun 10, 2024



In Multi-agent Reinforcement Learning (MARL), accurately perceiving opponents' strategies is essential for both cooperative and adversarial contexts, particularly within dynamic environments. While Proximal Policy Optimization (PPO) and related algorithms such as Actor-Critic with Experience Replay (ACER), Trust Region Policy Optimization (TRPO), and Deep Deterministic Policy Gradient (DDPG) perform well in single-agent, stationary environments, they suffer from high variance in MARL due to non-stationary and hidden policies of opponents, leading to diminished reward performance. Additionally, existing methods in MARL face significant challenges, including the need for inter-agent communication, reliance on explicit reward information, high computational demands, and sampling inefficiencies. These issues render them less effective in continuous environments where opponents may abruptly change their policies without prior notice. Against this background, we present OPS-DeMo (Online Policy Switch-Detection Model), an online algorithm that employs dynamic error decay to detect changes in opponents' policies. OPS-DeMo continuously updates its beliefs using an Assumed Opponent Policy (AOP) Bank and selects corresponding responses from a pre-trained Response Policy Bank. Each response policy is trained against consistently strategizing opponents, reducing training uncertainty and enabling the effective use of algorithms like PPO in multi-agent environments. Comparative assessments show that our approach outperforms PPO-trained models in dynamic scenarios like the Predator-Prey setting, providing greater robustness to sudden policy shifts and enabling more informed decision-making through precise opponent policy insights.
A Graph Neural Network-Based QUBO-Formulated Hamiltonian-Inspired Loss Function for Combinatorial Optimization using Reinforcement Learning
Nov 27, 2023Quadratic Unconstrained Binary Optimization (QUBO) is a generic technique to model various NP-hard Combinatorial Optimization problems (CO) in the form of binary variables. Ising Hamiltonian is used to model the energy function of a system. QUBO to Ising Hamiltonian is regarded as a technique to solve various canonical optimization problems through quantum optimization algorithms. Recently, PI-GNN, a generic framework, has been proposed to address CO problems over graphs based on Graph Neural Network (GNN) architecture. They introduced a generic QUBO-formulated Hamiltonian-inspired loss function that was directly optimized using GNN. PI-GNN is highly scalable but there lies a noticeable decrease in the number of satisfied constraints when compared to problem-specific algorithms and becomes more pronounced with increased graph densities. Here, We identify a behavioral pattern related to it and devise strategies to improve its performance. Another group of literature uses Reinforcement learning (RL) to solve the aforementioned NP-hard problems using problem-specific reward functions. In this work, we also focus on creating a bridge between the RL-based solutions and the QUBO-formulated Hamiltonian. We formulate and empirically evaluate the compatibility of the QUBO-formulated Hamiltonian as the generic reward function in the RL-based paradigm in the form of rewards. Furthermore, we also introduce a novel Monty Carlo Tree Search-based strategy with GNN where we apply a guided search through manual perturbation of node labels during training. We empirically evaluated our methods and observed up to 44% improvement in the number of constraint violations compared to the PI-GNN.
Understanding the Usage of QUBO-based Hamiltonian Function in Combinatorial Optimization over Graphs: A Discussion Using Max Cut (MC) Problem
Aug 27, 2023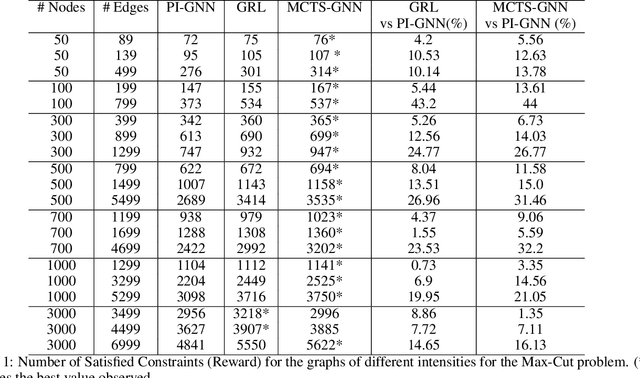
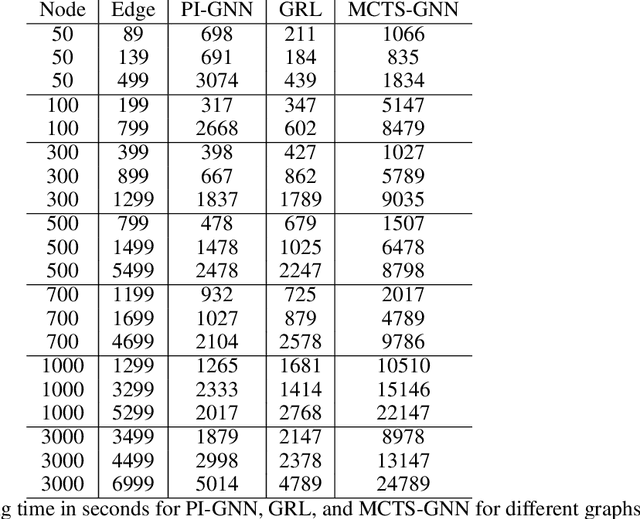
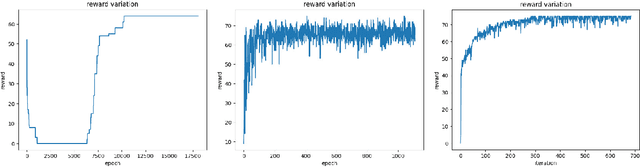
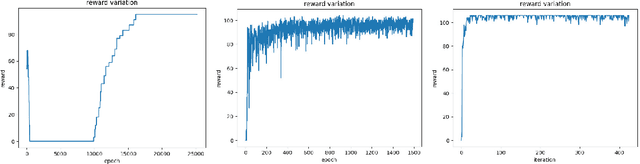
Quadratic Unconstrained Binary Optimization (QUBO) is a generic technique to model various NP-hard combinatorial optimization problems in the form of binary variables. The Hamiltonian function is often used to formulate QUBO problems where it is used as the objective function in the context of optimization. In this study, we investigate how reinforcement learning-based (RL) paradigms with the presence of the Hamiltonian function can address combinatorial optimization problems over graphs in QUBO formulations. We use Graph Neural Network (GNN) as the message-passing architecture to convey the information among the nodes. We have centered our discussion on QUBO formulated Max-Cut problem but the intuitions can be extended to any QUBO supported canonical NP-Hard combinatorial optimization problems. We mainly investigate three formulations, Monty-Carlo Tree Search with GNN-based RL (MCTS-GNN), DQN with GNN-based RL, and a generic GNN with attention-based RL (GRL). Our findings state that in the RL-based paradigm, the Hamiltonian function-based optimization in QUBO formulation brings model convergence and can be used as a generic reward function. We also analyze and present the performance of our RL-based setups through experimenting over graphs of different densities and compare them with a simple GNN-based setup in the light of constraint violation, learning stability and computation cost. As per one of our findings, all the architectures provide a very comparable performance in sparse graphs as per the number of constraint violation whreas MCTS-GNN gives the best performance. In the similar criteria, the performance significantly starts to drop both for GRL and simple GNN-based setups whereas MCTS-GNN and DQN shines. We also present the corresponding mathematical formulations and in-depth discussion of the observed characteristics during experimentations.