 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMD-BERT: Action Recognition in Dark Videos via Dynamic Multi-Stream Fusion and Temporal Modeling
Feb 06, 2025



Action recognition in dark, low-light (under-exposed) or noisy videos is a challenging task due to visibility degradation, which can hinder critical spatiotemporal details. This paper proposes MD-BERT, a novel multi-stream approach that integrates complementary pre-processing techniques such as gamma correction and histogram equalization alongside raw dark frames to address these challenges. We introduce the Dynamic Feature Fusion (DFF) module, extending existing attentional fusion methods to a three-stream setting, thereby capturing fine-grained and global contextual information across different brightness and contrast enhancements. The fused spatiotemporal features are then processed by a BERT-based temporal model, which leverages its bidirectional self-attention to effectively capture long-range dependencies and contextual relationships across frames. Extensive experiments on the ARID V1.0 and ARID V1.5 dark video datasets show that MD-BERT outperforms existing methods, establishing a new state-of-the-art performance. Ablation studies further highlight the individual contributions of each input stream and the effectiveness of the proposed DFF and BERT modules. The official website of this work is available at: https://github.com/HrishavBakulBarua/DarkBERT
ActNetFormer: Transformer-ResNet Hybrid Method for Semi-Supervised Action Recognition in Videos
Apr 09, 2024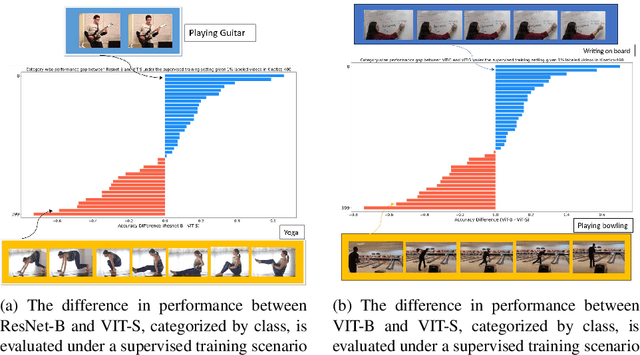

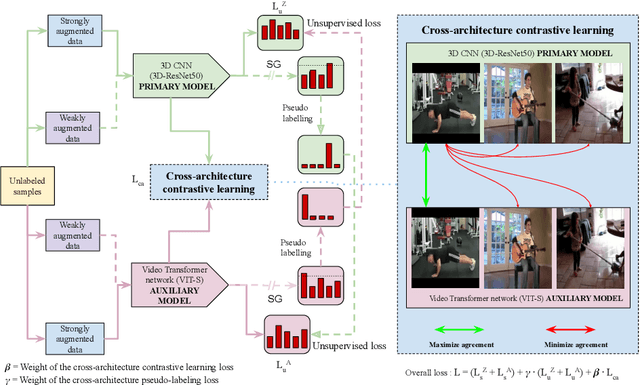

Human action or activity recognition in videos is a fundamental task in computer vision with applications in surveillance and monitoring, self-driving cars, sports analytics, human-robot interaction and many more. Traditional supervised methods require large annotated datasets for training, which are expensive and time-consuming to acquire. This work proposes a novel approach using Cross-Architecture Pseudo-Labeling with contrastive learning for semi-supervised action recognition. Our framework leverages both labeled and unlabelled data to robustly learn action representations in videos, combining pseudo-labeling with contrastive learning for effective learning from both types of samples. We introduce a novel cross-architecture approach where 3D Convolutional Neural Networks (3D CNNs) and video transformers (VIT) are utilised to capture different aspects of action representations; hence we call it ActNetFormer. The 3D CNNs excel at capturing spatial features and local dependencies in the temporal domain, while VIT excels at capturing long-range dependencies across frames. By integrating these complementary architectures within the ActNetFormer framework, our approach can effectively capture both local and global contextual information of an action. This comprehensive representation learning enables the model to achieve better performance in semi-supervised action recognition tasks by leveraging the strengths of each of these architectures. Experimental results on standard action recognition datasets demonstrate that our approach performs better than the existing methods, achieving state-of-the-art performance with only a fraction of labeled data. The official website of this work is available at: https://github.com/rana2149/ActNetFormer.