 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Urdu Caption Generation using Attention based LSTMs
Aug 02, 2020
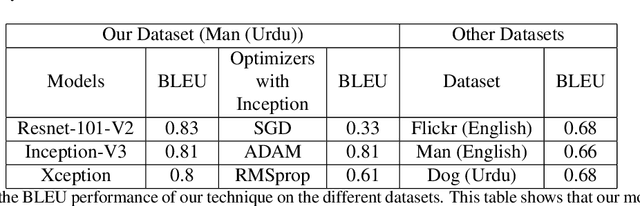
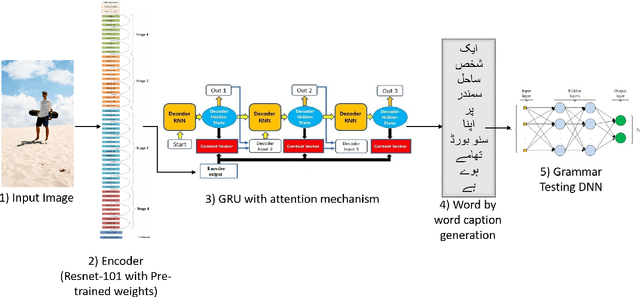

Recent advancements in deep learning has created a lot of opportunities to solve those real world problems which remained unsolved for more than a decade. Automatic caption generation is a major research field, and research community has done a lot of work on this problem on most common languages like English. Urdu is the national language of Pakistan and also much spoken and understood in the sub-continent region of Pakistan-India, and yet no work has been done for Urdu language caption generation. Our research aims to fill this gap by developing an attention-based deep learning model using techniques of sequence modelling specialized for Urdu language. We have prepared a dataset in Urdu language by translating a subset of "Flickr8k" dataset containing 700 'man' images. We evaluate our proposed technique on this dataset and show that it is able to achieve a BLEU score of 0.83 on Urdu language. We improve on the previously proposed techniques by using better CNN architectures and optimization techniques. Furthermore, we also tried adding a grammar loss to the model in order to make the predictions grammatically correct.