 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularization and Global Optimization in Model-Based Clustering
Feb 05, 2023



Due to their conceptual simplicity, k-means algorithm variants have been extensively used for unsupervised cluster analysis. However, one main shortcoming of these algorithms is that they essentially fit a mixture of identical spherical Gaussians to data that vastly deviates from such a distribution. In comparison, general Gaussian Mixture Models (GMMs) can fit richer structures but require estimating a quadratic number of parameters per cluster to represent the covariance matrices. This poses two main issues: (i) the underlying optimization problems are challenging due to their larger number of local minima, and (ii) their solutions can overfit the data. In this work, we design search strategies that circumvent both issues. We develop efficient global optimization algorithms for general GMMs, and we combine these algorithms with regularization strategies that avoid overfitting. Through extensive computational analyses, we observe that global optimization or regularization in isolation does not substantially improve cluster recovery. However, combining these techniques permits a completely new level of performance previously unachieved by k-means algorithm variants, unraveling vastly different cluster structures. These results shed new light on the current status quo between GMM and k-means methods and suggest the more frequent use of general GMMs for data exploration. To facilitate such applications, we provide open-source code as well as Julia packages ("UnsupervisedClustering.jl" and "RegularizedCovarianceMatrices.jl") implementing the proposed techniques.
Community Detection for Power Systems Network Aggregation Considering Renewable Variability
Nov 08, 2019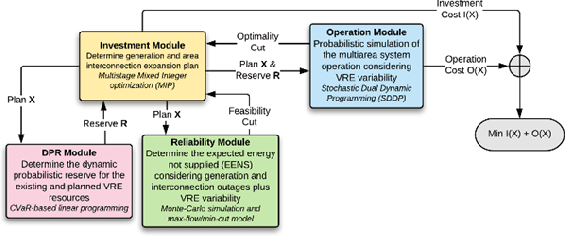
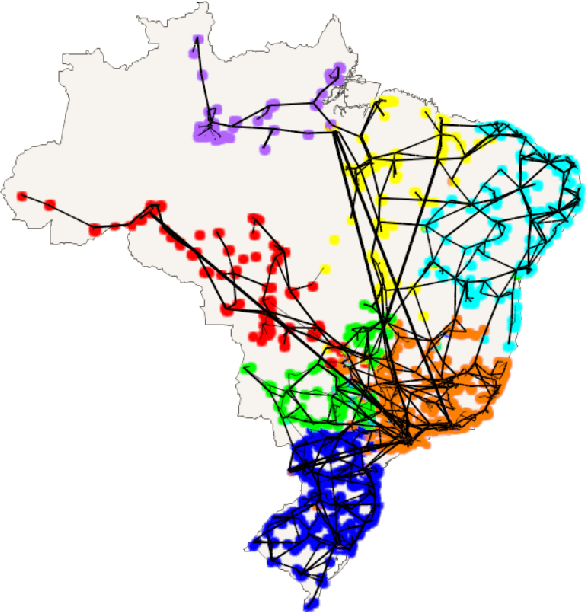
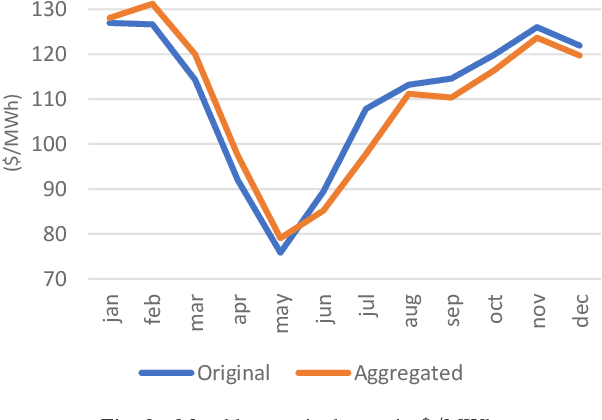
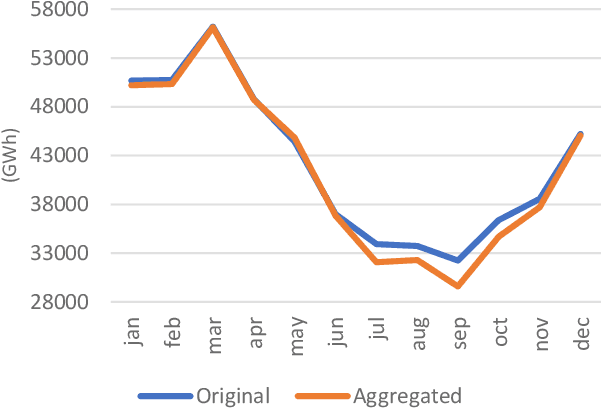
The increasing penetration of variable renewable energy (VRE) has brought significant challenges for power systems planning and operation. These highly variable sources are typically distributed in the grid; therefore, a detailed representation of transmission bottlenecks is fundamental to approximate the impact of the transmission network on the dispatch with VRE resources. The fine grain temporal scale of short term and day-ahead dispatch, taking into account the network constraints, also mandatory for mid-term planning studies, combined with the high variability of the VRE has brought the need to represent these uncertainties in stochastic optimization models while taking into account the transmission system. These requirements impose a computational burden to solve the planning and operation models. We propose a methodology based on community detection to aggregate the network representation, capable of preserving the locational marginal price (LMP) differences in multiple VRE scenarios, and describe a real-world operational planning study. The optimal expected cost solution considering aggregated networks is compared with the full network representation. Both representations were embedded in an operation model relying on Stochastic Dual Dynamic Programming (SDDP) to deal with the random variables in a multi-stage problem.